*Update – part 2 of this series is now live, and can be found here*
In times of yore, those who maketh the houses of data would bring forth vast swathes of tables and hurl them down in the forts of staging. Here the ancient priests of Ee, Tee and El would perform arcane magicks and transform these rows of chaos into purest order. This order would be rebuilt into the fabled Data Warehouses, and all who looked upon them would gasp in awe and wonder.
But that was then. Today’s data world is different, isn’t it? Data is varied. It’s big and small, fast and slow. It’s tougher to wrangle and make into shapes fit for use. But through all of this, we still need the hallowed, fabled, data warehouse.
Or do we?
This post is basically me exploring a different approach to building a data warehouse that’s based on the data lake paradigm and a form of ELT (Extract, Transform and Load), but leaves out the actual data warehouse part. I’m still going to build a star schema, but it’s going to be file based, using modern data engineering tools to do the munging and “schema-tizing” before sucking into a semantic layer for reporting. It’s also me exploring the capabilities of my current favourite tool – Azure Databricks.
What are the potential benefits of this approach? A few spring to mind, such as cost, flexibility and simplicity. By keeping all the processing within the data lake means it’s easier to control and govern, and the reduced data movement (you’re not copying into a data warehouse) makes an altogether more simpler structure.
Conversely, I’m well aware that this approach brings it’s own challenges. Traditional data warehouse constructs like Slowly Changing Dimensions, Surrogate Keys and other elements of the Kimball checklist will be harder or even not possible with this, so it won’t suit every scenario.
My aim here though was simple – can we build a BI solution without the data warehouse element and is it a viable approach for certain scenarios?
In short, the solution looks like this:

The above construct largely follows the traditional ETL model with data flowing in from source systems, and comprises the following:
- Data ingested as raw files into a staging zone in the data lake
- Files processed using data engineering platform into cleansed outputs
- Scrubbed files then shaped and moved into relevant serving zones. In this example I’ve kept it simple, with one zone for the star schema files and one for a data assets folder that provides cleansed, curated data sets to be consumed by analysts and data scientists.
- The star schema files are subsequently loaded into a semantic layer for enterprise reporting and ad hoc slice n’ dice functionality, whilst the asset files are consumed using the variety of tools preferred by today’s analysts.
To bring this to life, I’ll be using a handful of Azure data services for the relevant solution components –
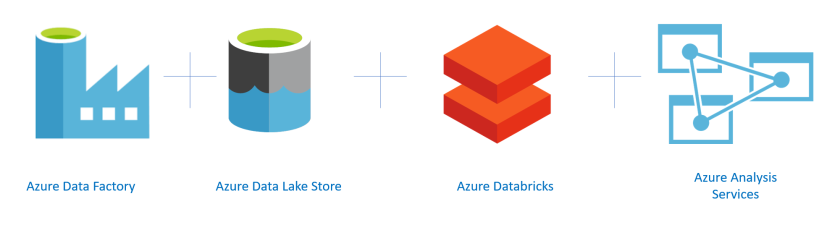
In this example, I’ll be using an Azure SQL Database as my data source with the AdventureworksLT database.
Prerequisites
- An Azure Data Lake Store
- An Azure Databricks Workspace
- Azure Analysis Services Server
- An Azure Data Factory Account
- Azure SQL Database with AdventureWorksLT sample database installed
For each of the above, ensure you put everything in the same Azure region.
Extract
There are plenty of options in this space that could move data from source to my lake, including ETL tools such as SSIS, Talend and Azure Data Factory. For this example I’m using Azure Data Factory (version 2), with copy activities moving data from my source SQL database and dropping as *.csv files. I’m also taking advantage of the new Databricks functionality built into Azure Data Factory that allows me to call a Databricks Notebook as part of the data pipeline.

The above data factory copies the source tables into my “raw” directory, and from there I process the files, with the end result being to create my dimension and fact files ready to be loaded into Azure Analysis Services.
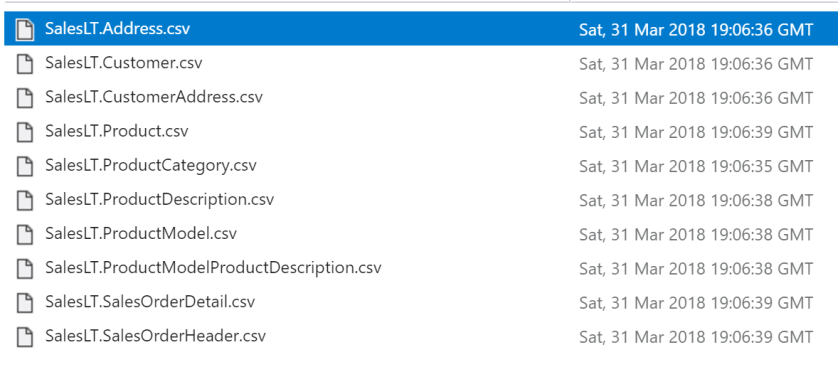
Load Files Into Spark DataFrames
With this files safely copied into our raw landing zone, I can now extract the source tables directly into Spark DataFrames. An example is shown below for the product table. We create a DataFrame for each source file.

Transform
With the DataFrames created, I then create temporary SQL tables from them so that we can use SQL code to define my dimension. You can of course manipulate them natively as DataFrames using Python/Scala/R if you’re more familiar with those languages. I’m a SQL dude, and am familiar in building data warehouse routines in SQL code so have opted for that method here.

With these views created we can use good ‘old SQL to create DataFrames that reflect the dimensions and facts we want to load into Azure Analysis Services.
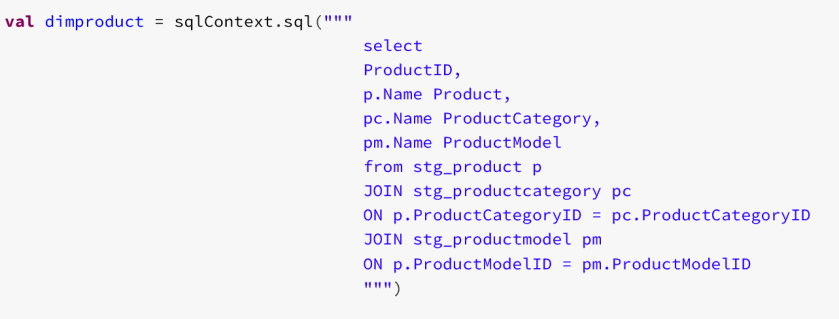
and fact tables:

When I run my notebook now I have my dimensional and fact tables created as Spark dataframes. In order for them to be consumed by Azure Analysis Services I need to write the dataframes into CSV files that can then be imported into my tabular model.
Output Dimension and Fact Files
Writing files back from Spark into csv wasn’t as seamless as I thought it would be. Whilst the commands are fairly straight forward, as Spark is a distributed system it writes multiple files as an output, including crc and SUCCESS metadata files. It also doesn’t name them as the file you specify, but instead names it based on the partition name.
We don’t need these files, and need a proper, consistent filename, so I wrote some extra code to rename and move the files back under our Data Warehouse directory.

With all this done, it leaves us nicely with a set of files ready for ingestion into Azure Analysis Services, which is the subject of Part 2 of this series.

Coming in the second and final part of this series…
- Build an Azure Analysis Services model directly off the dimension and fact files within the Data Lake Store
- String it all together using Azure Data Factory
Part 2 is now live, and can be found here….

Reblogged this on Another Blog on Cloud Data and commented:
Very interesting take on data warehousing options, definitely worth a read
LikeLike
Thanks for the article. Just a note on collect() – you probably wouldn’t use that in production environment as it loads all the data to the driver and a memory exception will be thrown if the dataset is too large to fit in memory. Tom
LikeLike
I’ve been very keen to cut the middle man here – SQL database, therefore I’ve been exploring the approach described in the article, and it looks like there’s a number of challenges:
– There does not seem to be simple / inexpensive query tool for data lake Gen2 (similar to SQL language in relational databases) where you could do all sorts of operations on datasets: joins, sorts, groupings, etc, etc.
In a common data warehouse environment one would need a simple and efficient query tool for debugging and troubleshooting. There is Data Lake Analytics that only supports Data Lake gen1 (which is on the way to be retired sometime in future).
– Normally quite a few of dimensions in medium to large DW environments are Slowly-Changing / Type2 dimensions
This will require change detection / history tracking on those datasets which, as you mentioned in the article, is a problem for this approach
– Normally surrogate keys will be all over the star schema
You are quite right, in common DW implementation there will be a lot of complex transformations, business logic and remodelling, between the source dataset and the resulting dimension or fact
Do you think Databricks or Azure Data Factory Data Flows are as good of a tool for the job as SQL?
LikeLike
Thanks for the comment. I’m due a refresh of this article as this space has moved on significantly since I wrote it. In response to some of your questions (but I’ll look to put this in more detail in a proper post) there’s some high level things I’d be looking at now –
– Serverless SQL Pools on the new Synapse offering. This allows for T-SQL code on top of data lake. You can even look to CETAS statements to transform raw data tables into dimensions/facts and store the results as parquet. AAS now has a connector to allow access to ADLS Gen 2 – what I HAVEN’T tried yet is that this works with external tables created inside ADLS from CETAS. PBI itself has come on in leaps and bounds too meaning that is effectively a superset of AAS now, so I expect more patterns to see PBI Premium as both the model and visual layer going forwards.
– Yep the SCD challenge is is still a challenge for this kind of approach (if you really want to not use a Dedicated SQL Pool). I’ve seen patterns where rather than tracking history as an SCD, instead you simply append the new load as a new partition to the dimension table every load. Queries can then look at the relevant partition for the “effective” date they’re after. This will swell the size of the tables massively, but as storage is dirt cheap it could be an approach you consider.
– Serverless SQL Pools don’t support surrogate key functionality natively (as by their very nature are just querying external files). Data Flows & Dedicated SQL Pools are fine to handle/create them – but then we’re bringing in other components into what I was trying to keep a relatively simple pattern.
I intended to cover all this in an upcoming post – thanks for the points as they’re ones I’d picked up when I first wrote it. The landscape has moved on a lot so it will be good to revisit. With PBI Data Flows, ADF Data Flows, Synapse etc – the choices are wide, and there’s often many ways of doing it now with none of them necessarily being wrong.
For your last question (Databricks/Data Flows vs SQL) – I don’t think this is a binary answer. If you want to apply visual transforms and stay out of the code, then Data Flows are an excellent option, and now have a lot of capabilities necessary for loading a modern data warehouse. Saying all that, I personally am a fan of orchestrating SQL code in my pipelines as it allows me to adopt more of a “framework” to my approach – dynamically fed stored procs, merge statements etc. But if there are things that are just cumbersome via SQL code and if it’s more an outlier requirement I’m quite happy to use flows instead. It’s all down to the requirement, skills in the team etc.
Same for Databricks/Spark – a lot of data engineers are now favoring Spark/Python for data engineering pipelines. I’m a SQL guy myself, so lean towards that. But if you’ve got strong Python skills and want a code driven approach, fill your boots. There is no better or worse in my opinion, just different approaches depending on various factors.
LikeLike