
Note, this article is the first in a series of articles focussing on common use cases and challenges in Healthcare and specifically from what I’ve seen in the NHS working on many exciting projects with customers around the UK. Future ones will include:
- Delivering Interoperability For Analytics in the Healthcare with Databricks (Part 1 – Ingestion and Data Analysis) (This one)
- Delivering Interoperability For Analytics in the Healthcare with Databricks (Part 2 – Advanced Analytics)
- Secure Data Sharing in Healthcare with Delta Share
- Databricks Marketplace and Private Exchange – Creating a private marketplace for collaborating organisations
- Databricks Cleanrooms – Secure collaboration and research in trusted environments
- Databricks SQL + Delta Live Tables – Data Warehousing – Databricks Style
- Secure Data Environments -Secure, Open Collaboration with Databricks
- More to come…
Introduction
In the evolving landscape of healthcare, healthcare organisations face significant challenges in achieving effective interoperability—a crucial aspect for enhancing patient care and operational efficiency. The diversity and volume of data across various health systems necessitates a robust solution for seamless integration and analysis. In this space, Databricks emerges as a powerful and capable technology, offering advanced analytics and data processing capabilities that are built on the Lakehouse paradigm and leveraging open standards. Its ability to streamline data management, support standardized healthcare protocols like FHIR and OMOP, and facilitate real-time decision-making presents a significant opportunity for healthcare organisations to tackle these interoperability hurdles directly.
In my role as a solutions architect for Databricks working exclusively with the NHS and related agencies in UK public sector healthcare, one of the most common challenges faced is achieving effective interoperability. Namely, how can information from different technology systems and applications be exchanged to allow the secure sharing and utlisation of patient data across healthcare providers and systems? Having effective interoperability is crucial for coordinated care and service delivery and for ultimately delivering better health outcomes.
Within healthcare the diversity and volume of data and systems is vast, and with the demands of modern healthcare on services only growing, the need for effective interoperability approaches is more important than ever.
In this article I will explain how, by leveraging standardised protocols like FHIR and OMOP and combining with Databrick’s inherent capabilities for advanced analytics and data processing, healthcare organisations can address these challenges head on.
What is Databricks?
For a deep dive into what Databricks is, see here. For the TLDR, Databricks is a unified, open, cloud-based platform that provides enterprise-grade data analytics and AI, enabling large-scale data processing, analytics, machine learning, and collaborative data science, all built on open foundations such as Delta Lake, Apache Spark, Delta Share and MLFlow and deployable across all the main cloud vendors – Azure, AWS and GCP.
Interoperability Approaches In Healthcare
Before I address directly how Databricks addresses these challenges, I’ll first address how a common method of delivering interoperability is used within healthcare, namely the Fast Healthcare Interoperability Resources, or FHIR.
FHIR is a standard developed by HL7 for enhancing healthcare data exchange and interoperability and facilitates the sharing of health information among various systems, applications, and devices. It achieves this by providing a standardized framework for structuring and transmitting electronic healthcare data. FHIR’s resources represent diverse aspects of health information, enabling the exchange of patient demographics, clinical records, medications, and more.

FHIR plays a vital role in healthcare by promoting interoperability, allowing different systems to communicate seamlessly. It supports EHR integration, enabling electronic health record systems to connect with other healthcare applications, including mobile health apps and analytics platforms. FHIR also aids research by facilitating data aggregation and analysis, benefiting both researchers and healthcare providers. Overall, FHIR contributes significantly to modernizing healthcare, aiding innovation, and improving patient care coordination.
Databricks and FHIR together
Whilst FHIR is an established protocol, there are specific challenges that need to be overcome to work with it effectively:
- Converting FHIR (often serialized in JSON format) to tables for analytics and in accepted industry models, such as OMOP
- Supporting streaming, real-time data to reflect the dynamic nature of patient health
- Combining FHIR with unstructured data, or other structured data models, outside of those bundles in a common data model
- Connecting data to advanced analytics and machine learning tooling
To support this approach and provide these capabilities on FHIR, Databricks developed the dbignite library which is best described as:
“…an open-source toolkit built to address these challenges [of leveraging FHIR], effectively translating transactional bundles into patient analytics at scale with the Lakehouse.”
Further information on dbgnite can be found here, but for the rest of this article I’ll show you Databricks can do this, and how you can access these capabilities today using a very simple demo that you can follow along with yourself.
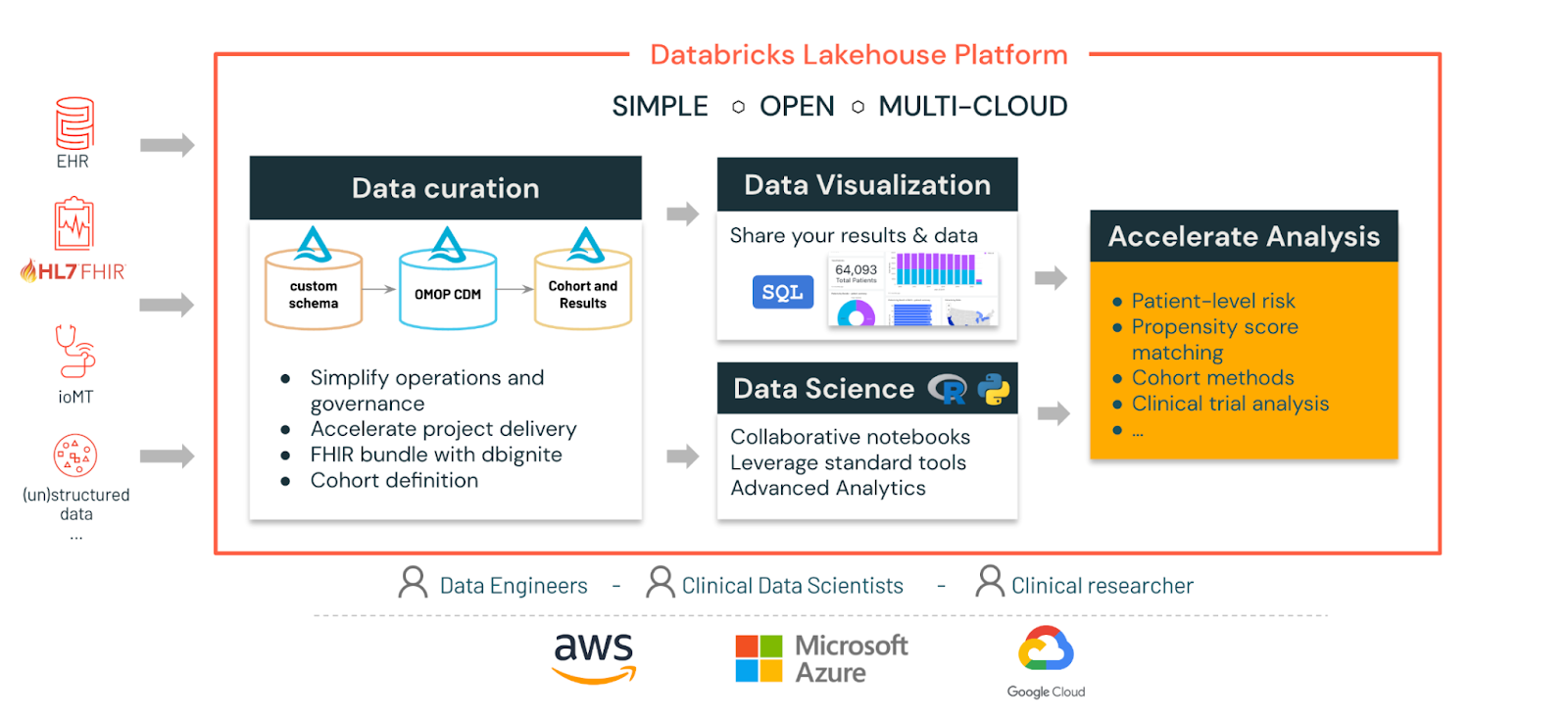
Achieving Interoperability with Databricks
In this demo, I’ll show you how you can use Databricks to the do the following:
- Ingest and parse FHIR bundles using the dbgnite library
- Parse and transform these into OMOP standard tables for reporting and analysis
- Give examples of how you can apply analysis against your tables
- In the second part of this article I will show you can perform advanced analytics such as cohort analysis and predictive machine learning based on patient conditions
Note, follow on yourself by accessing these notebooks here
Prequisites (For this Demo)
- Access to a Databricks Workspace and a running cluster (a single node will be fine)
- Download the FHIR Solution Accelerator here
Ingesting and Parsing FHIR Bundles
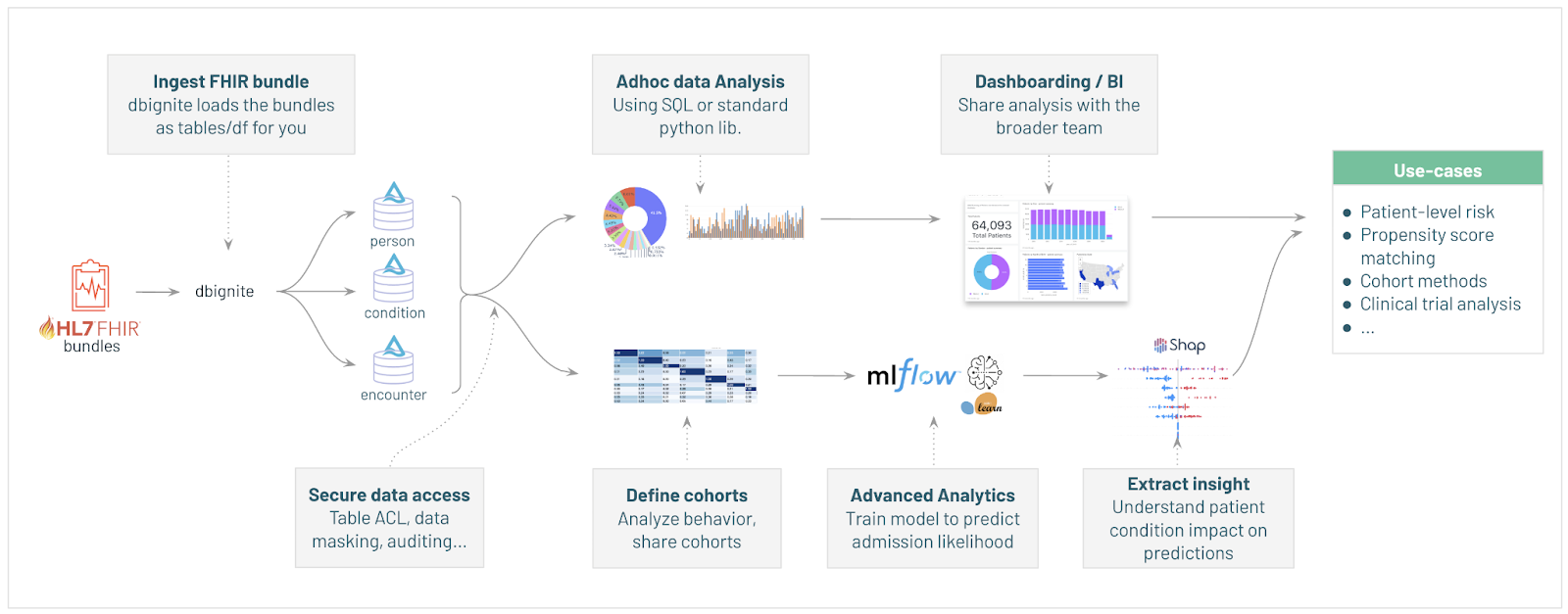
The first step is to ingest and parse FHIR bundles with Databricks. To do this, we first need to install the dbignite library:
In your Databricks workspace, either create a new Notebook or Import the downloaded Notebooks for this demo (see above)
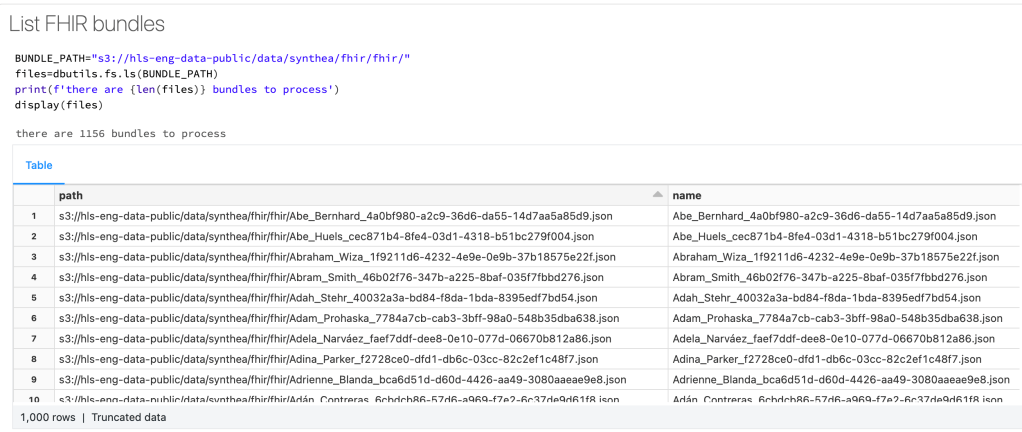
%pip install git+https://github.com/databricks-industry-solutions/dbignite.git@aa853e2e2de487318d14683e56ce8e36dd0c4d24From here we can explore our FHIR bundles in cloud storage (these are example files provided for this demonstration):
BUNDLE_PATH="s3://hls-eng-data-public/data/synthea/fhir/fhir/"
files=dbutils.fs.ls(BUNDLE_PATH)
print(f'there are {len(files)} bundles to process')
display(files)And see our available FHIR bundles:
From here we can take a look at one of these files to see a typical FHIR bundle using the following command:
print(dbutils.fs.head(files[0].path))
With our data available, we now employ a series of steps that employs the capabilities of dbignite in Databricks that automatically transforms the FHIR bundles into an OMOP-style database and tables that can then be used for our downstream analytics and processing:

Run the above, and when the commands have completed we can see our created tables inside Databricks – parsed, loaded and ready for use. We can see our created tables using a simple SQL command:
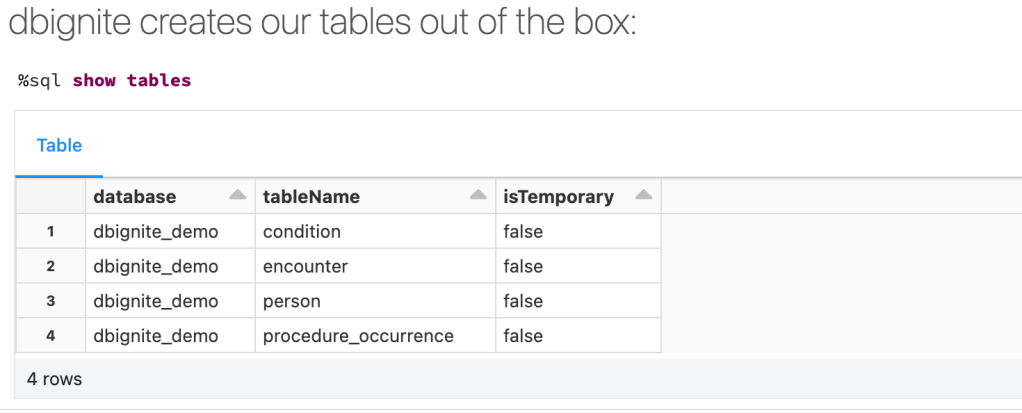
And start exploring them with familiar languages such as SQL or Python:

From here we can extend this to more advanced queries on our extracted tables:

We can also leverage dbignite to create our very own patient snapshot, as an example:
Transform from CDM to a patient dashboard
cdm2dash_transformer=CdmToPersonDashboard(spark)
dash_model=PersonDashboard()
cdm2dash_transformer.transform(cdm_model,dash_model)
person_dashboard_df = dash_model.summary()And query this snapshot for analysis:
from pyspark.sql import functions as F
display(
person_dashboard_df
.filter("person_id='6efa4cd6-923d-2b91-272a-0f5c78a637b8'")
.select(F.explode('conditions').alias('conditions'))
.selectExpr('conditions.condition_start_datetime','conditions.condition_start_datetime','conditions.condition_status')
)
Conclusion (Part 1)
This first article has shown how by leveraging the powerful capabilities of Databricks coupled with dbignite you can easily ingest and transform your FHIR data into OMOP tables and columns that can be easily queried for analysis and reporting.
In the next part of this article I’ll show you how you can extend this to apply more advanced analytics such as Cohort Analysis and creating predictive models on your data.
Useful Links
Project DbIgnite – Interoperability with Databricks
Solution Accelerator – FHIR Interoperability with Databricks & dbignite
