Part 1 of this series can be found here.
In my previous post I discussed and explored the feasibility of building a simplified reporting platform in Microsoft Azure that did away with the need for a relational data warehouse. In this article, I proposed that we land, process and present curated datasets (both dimensional files for our data warehouse “layer” and other data assets for our data scientists to work with) within Azure Data Lake Store, with the final step being to product a series of dimension and fact files to be consumed by our semantic layer. The diagram below highlights this approach:

At the end of the previous post I’d produced our data warehouse files (dimensions and facts) and in this second and final part I will show how we consume these files with our semantic layer (Azure Analysis Services) to finally present a business-friendly reporting layer without a data warehouse in size.
Semantic Layer
A semantic layer presents the business view of the data model, and allows users to interact with the layer without needing knowledge of the underlying schema or even knowledge of writing SQL code. In the words of my colleague Christian Wade, it’s “clicky-clicky draggy droppy” reporting that provides a single version of the truth without risk of users creating inaccurate measures by a misplaced join or incorrect Group By statement.
Microsoft’s semantic layer offering is Azure Analysis Services, and allows users to connect to models built with Analysis Services using any compliant tool, such as Power BI and Tableau.
I create an Azure Analysis Services project in Visual Studio, and connect to my Azure Data Lake Store from Part 1 (Ensure you change your model to use the latest SQL Server 2017/Azure Analysis Services Compatibility Level) :
In the Query Editor I create queries that pull in the csv files that I created earlier for DimProduct, DimCustomer and FactSales:
Note, whilst it’s relatively straight forward to import csv files into Azure Analysis Services from Data Lake Store, my colleague Kay Unkroth wrote a great article that makes this much easier, and I use this method in my solution. Please see this article for further details.
Once the tables have been imported into Azure Analysis Services, it’s then a simple feat to define our star schema and create a couple of measures:

We then publish our Analysis Services model to the Azure Analysis Services Server we created in part 1, and connect to it using Power BI:
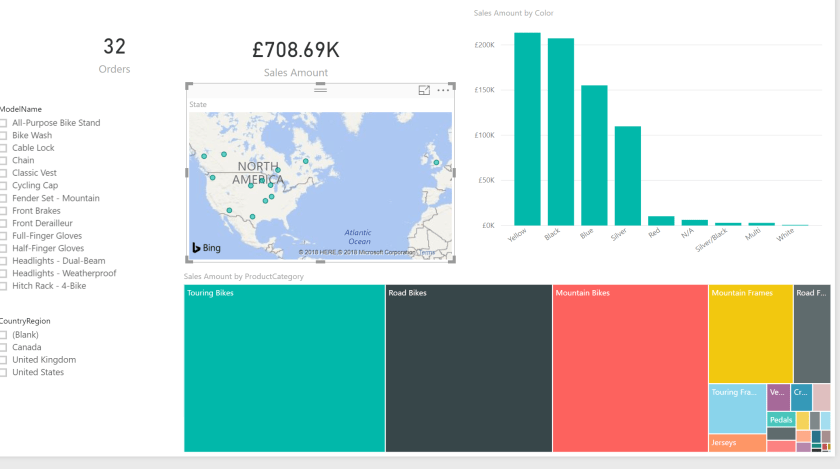
That’s it, all done!
Not quite…
Refresh and Orchestration
So we’ve shown now that you can ingest, process and serve data as dimensional constructs using Databricks, Data Lake Store and Analysis Services. However this isn’t at all useful if the pattern can’t be repeated on a schedule. From Part 1, we use Azure Data Factory to copy data from our sources and also to call our Databricks notebook that does the bulk of the processing. With our Analysis Services model now published, we simply need to extend our Data Factory pipeline to automate processing the model.
Logic Apps
There are a few methods out there for refreshing an Azure Analysis Services cube, including this one here. However I particularly like the use of Azure Logic Apps for a code-lite approach to orchestration. Using Logic Apps I can call the Azure Analysis Services API on demand to process the model (refresh with latest data from our data store). The Logic App presents a URI that I can then call a POST against that triggers the processing.
Jorg Klein did an excellent post on this subject here, and it’s his method I use in the following example:

Once you’ve verified that the Logic App can call the Azure Analysis Services refresh API successfully, you simply need to embed it into the Data Factory workflow. This is simply a matter of using the Data Factory “Web” activity that is used to call the URI obtained from the Logic App you created above:

Our final (simplified for this blog post) Data Factory looks like this, with the Web Activity highlighted.
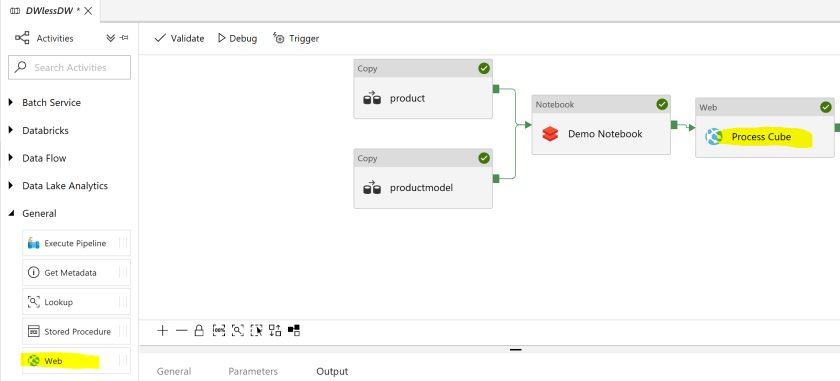
A simple test of the Data Factory pipeline verifies that all is working.
Conclusion
So, there you have it. My aim in this post was to see if we could create a simplified data warehouse-like approach that did away with a relational data warehouse platform yet still provided the ability to serve the various workloads of a modern data platform. By keeping the data all in one location (our data lake), we minimize the amount of data movement, thus simplifying many aspects, including governance and architecture complexity.
In terms of how we did it:
- Ingested data from source systems using Azure Data Factory, landing these as CSV files in Azure Data Lake Store
- Azure Databricks was then used to process the data and create our dimensional model, writing back the data files into Azure Data Lake Store
- Azure Analysis Services ingested the the dimensional files into its in-memory engine, presenting a user friendly view that can be consumed by BI tools
- Refresh of the Analysis Services model was achieved using Azure Logic Apps, with this component being added to our data pipeline in Azure Data Factory
Is This A Viable Approach?
Simply put, I believe the approach can work, however I think it is definitely dependent on specific scenarios. You can’t, or at least, not very easily, create “traditional” data warehouse elements such as Slowly Changing Dimensions in this approach. The example proposed in these articles is a simple star schema model, with a “rebuilt-every-load” approach being taken as our data sets are very small. For large, enterprise scale data warehouse solutions you need to work in different ways with Data Lake Store than we would do with a traditional data warehouse pipeline. There are many other factors to discuss that would affect your decision but these are out of scope for this particular article.
So, can we build a datawarehouse-less data warehouse?
Yes we can.
Should we build them this way?
It depends, and it’s definitely not for everyone. But the joy of cloud is you can try things out quickly and see if they work. If they don’t, tear it down and build it a different way. One definite benefit of this particular solution is that it allows you to get started quickly for an alpha or POC. Sure you might need a proper RDBMS data warehouse further down the line, but to keep things simple get the solution up and running using an approach such as suggested in this article and “back fill” in with a more robust pipeline once you’ve got your transformation code nailed down.
Happy building.
Further Reading
Azure Analysis Services With Azure Data Lake Store
Process Azure Analysis Services Using Logic Apps
Operationalize Databricks Notebooks Using Azure Data Factory

Thanks for this two-part series! Helped my understanding of how these various products can plug together.
LikeLiked by 1 person