To gain the best loading performance with Azure SQL Data Warehouse, you want to leverage the power of PolyBase, which allows for massively parallel data loading into the underlying storage.
In standard scenarios, ETL developers using SSIS will leverage a data flow that takes data from a source (Database, File, etc) and load it directly into the target database:

Unfortunately, adopting this pattern with an SSIS data flow into Azure SQL Data Warehouse will not naturally leverage the power of PolyBase. In order to understand this we need to take a little peek under the covers of SQL Data Warehouse:
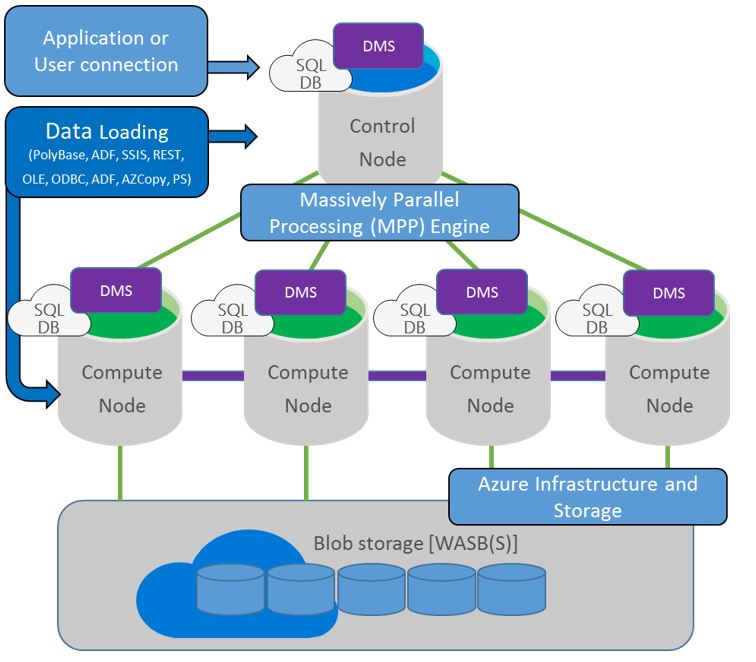
As part of the underlying architecture, SQL DW has at its head the Control Node. This node manages and optimizes queries, and serves as the access point for client applications when accessing the SQL DW cluster. What this means for SSIS, is that when it makes its connection to the SQL DW using standard data connectors, this connection is made to the Control Node:
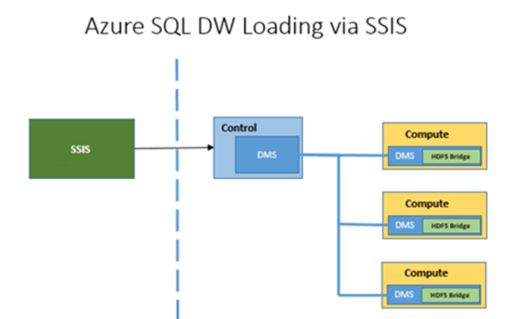
This method introduces a bottleneck as the Control node serves as the single throughput point for the data flow. As the Control node does not scale out, this limits the speed of your ETL flow.
As stated earlier, the most efficient way of loading into Azure SQL DW is to leverage the power of PolyBase in a process known as “Back Loading”:
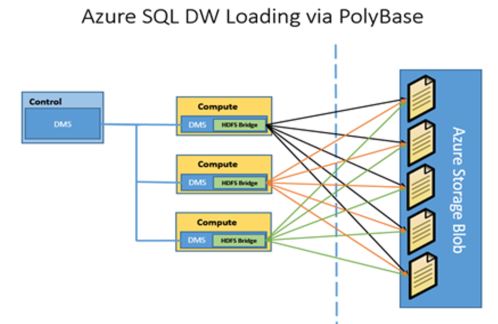
Using this method, data is bulk loaded in parallel from staging files held in Blob Storage or Azure Data Lake Store, which allows for the full data processing power of PolyBase to be used.
Leveraging Polybase Within SSIS
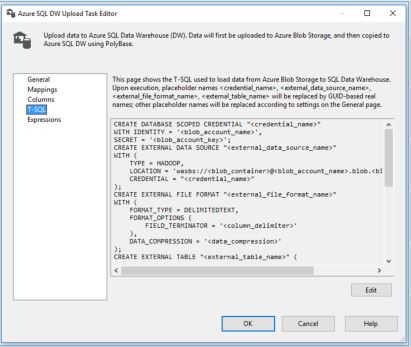
Previously, ingesting data from files into SQL DW using PolyBase was a slightly drawn out process of uploading files to storage, defining credentials, file formats and external table definitions before finally loading the data into SQL DW using a CTAS (Create Table As Select) statement. This works perfectly well, but introduces a lot of extra SQL coding on top of the norm.
Thankfully, with the SSIS Azure Feature Back, the above is now made much, much easier with the introduction of the Azure SQL DW Upload task. This process automates the creation of the SQL scripts required, allows you to seamlessly incorporate this task into an SSIS ETL process that will fully leverage Polybase.

Further Reading

Nice start, I worked with mitch at the NHS – he told me about your blog! Check out mine at padiganblog.wordpress.com
LikeLike