Extract, Transform & Load (ETL), or ELT, ETLT or whatever term we use nowadays, has been around for many decades. In terms of “what it is” – although I’m sure many database professionals will be familiar with the concept – I will defer to Wikipedia for a formal definition –
In computing, extract, transform, load (ETL) is a process in database usage to prepare data for analysis, especially in data warehousing[1]. The ETL process became a popular concept in the 1970s.[2] Data extraction involves extracting data from homogeneous or heterogeneous sources, while data transformation processes data by transforming them into a proper storage format/structure for the purposes of querying and analysis; finally, data loading describes the insertion of data into the final target database such as an operational data store, a data mart, or a data warehouse. A properly designed ETL system extracts data from the source systems, enforces data quality and consistency standards, conforms data so that separate sources can be used together, and finally delivers data in a presentation-ready format so that application developers can build applications and end users can make decisions
Courtesy Of – https://en.wikipedia.org/wiki/Extract,_transform,_load
Essentially, we take some data stuff, pull it out from its home, mash it into a nicer shape, then serve it to welcoming consumers. See below for a simple example I’m sure we’ve all seen before –
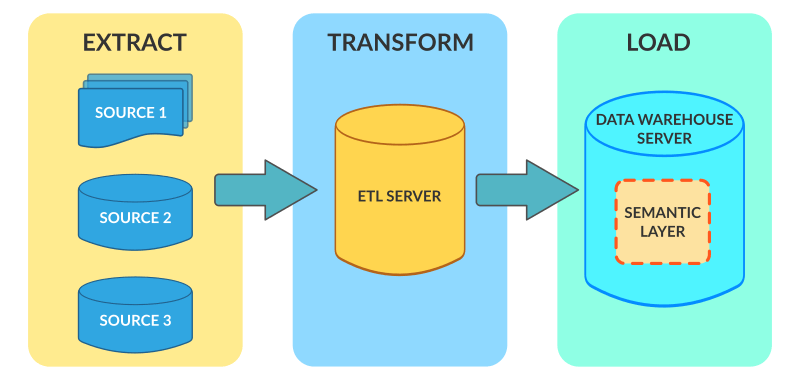
So, that’ll do for a definition, but for this post I’m not going into the deep details of how ETL processes are built, instead I’m going to provide some details of the available options in Azure, and when/why you would use them. There are many choices right now, so it felt a good time to summarize the offerings.
SSIS
SSIS (SQL Server Integration Services) has been around for many, many years. It’s very mature, has lots of supporting books, blogs and articles as to how to setup and develop with. Part of the SQL Server product stack, it provides connectors to many different sources and contains many different transformation tasks that can handle pretty much any kind of traditional ETL workflow. Whilst showing it’s age a little in terms of the UI, recent additions such as the Azure Feature Pack has meant it can be used for large scale ETL scenarios into Azure, and an extensive community backing has led to the emergence of such automated ETL build tools for SSIS such as BIML.
For on-premise ETL workloads, SSIS is still the go-to tool of choice for those invested in the Microsoft BI Stack. It’s fully integrated into SQL Server Data Tools and is well equipped to handle most workloads.
For those people moving to Azure and sunk a lot of development time into SSIS, have no fear. Whilst you can simply lift your SQL Server virtual machine running SSIS into the cloud and keep running as before, for those who want to leverage more PaaS-based approaches we now offer the facility to publish your SSIS packages directly into Data Factory, and call your packages within SSIS in a similar way that’s been done previously in SSIS Master-Child package patterns.

So, for those projects that are born in the cloud, can we use SSIS? Yes, sure you can. But if your using mainly cloud-born data or a hybrid, or if you need to move data at scale, then you probably need to look at something else, which leads us nicely to…
Data Factory
Now, up until recently, I wouldn’t have called Data Factory an ETL tool. I would instead have called it a Cloud-Based Data Orchestration Tool or an EPL (Extract, Process, Load) tool instead. The simple reason being is that Data Factory excelled (and still does) at moving data in bulk into the cloud and then orchestrating a series of processes underneath. An example would be to copy terrabytes of data from your on-premise databases, land it in a Azure Blob Storage or Data Lake, then call a processing engine on top to cleanse, transform and curate the data. This would be done using tools such as Azure Data Lake Analytics, HDInsight, Polybase via SQL Data Warehouse or, more recently, with Azure Databricks.
This kind of pattern (land -> process -> move on) evolved as part of the big data architecture pattern. It was becoming increasingly more difficult to do traditional ETL using tools like SSIS as the scale, size and shape of the data to be processed meant that you’d be hard pressed to fit it all in memory and process. What Data Factory allows you to do is copy the data at massive scale into your data lake, and then use processing tools more appropriate to the job to transform the data ready for usage downstream. This pattern is not dissimilar in fact to a common pattern seen in SSIS wherein developers simply used SSIS as the orchestrator and called a series of SQL Statements (often Stored Procedures) to handle the processing. When I used to build these packages on a weekly basis, this was the pattern I preferred as I liked to take advantage of the processing power of the underlying database engine. (The difference now is that it’s not just relational tables we’re dealing with and SQL code. It’s parquet, orc and avro combined with SQL and Python, mixed with a healthy does of JSON, NoSQL, Key Value pairs and Graph databases plus a sprinkle of Spark. For those of us who cut our teeth on SQL and “simple” ETL patterns – this isn’t Kansas anymore…)
This pattern with Data Factory is in reality an ELT (Extract, Load & Transform) approach. This means we extract, load it into the data lake, then process by the relevant tooling. This is compared to traditional ETL where the data is transformed in “flight” in the ETL tool in memory. With Data Factory we process the data where it is, using the engine best suited for that particular task.

Now, Data Factory has recently taken a massive step forwards to being a true ETL tool with the annoucment of Azure Data Factory Data Flows. Currently in private preview, this aims to bring true cloud-scale visual ETL into Data Factory by allowing you build data pipelines without having to write SQL, Python, R, Scale, Java as part of your activities. Instead, Dataflows allows developers to build a data flow using a visual environment and the actual work is pushed down into an Azure Databricks cluster underneath. This high level abstraction allows developers to focus on building the actual pipeline without having to code specific routines. This visual approach, combined with using Apache Spark (Databricks) as the processing engine under the hood, essentially means you get the best of both worlds. A visual ETL design experience to simplify development combined with a processing engine that can deal with the massive scale and variety of data often encountered when building modern data warehouses in the cloud.
Check out the preview video here, with a (not great) screen grab below –
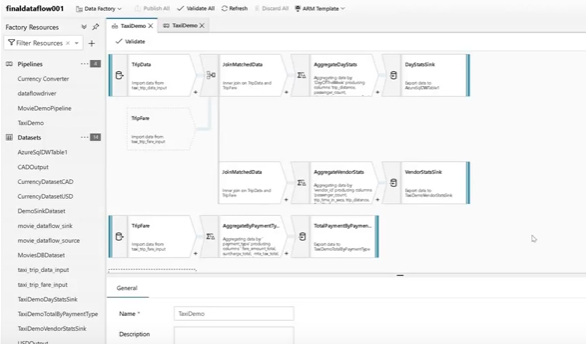
Data Flows are shaping to be an awesome addition to Data Factory and I’m really looking forward to the innovative patterns that emerge when it’s out in the big wide world.
Power BI Data Flows
Recently, we announced (or more specifically re-announced with a new name) Power BI Data Flows (Not to be confused with Data Factory Data Flows). For those familiar with Power BI it’s essentially the Power Query part (a really powerful data preparation and cleansing engine) that’s now been taken out and added to the Power BI Service as a cloud-based self serve data prep tool. The aim of this is to allow BI Developers and Analysts to build re-usable data flows that are published into Power BI. These flows can then be consumed as a data source by Power BI (and soon, other tools) Desktop. It also – and this is big – allows for the ability to write the output of the Data Flow back into Azure Data Lake (Gen 2), thus allowing the prepped data to be picked up and used by other tools. This latter functionality essentially democratizes ETL into the hands of the BI Developer or Analyst. Whereas previously it was often on the head of ETL developers or data engineers to build the pipelines for the analysts to consume, Dataflows now allows them to build these pipelines themselves and essentially giving them a full, end to end, analytics platform capability.
Essentially, with Power BI Dataflows, you can build the ETL, model the data, transform it into a reporting friendly structure (think Kimball-style dimensional models) and serve it, either within Power BI directly or to be consumed by other tools.
Another benefit of Power BI Data Flows is that it allows data transformation logic that had previously been locked to a specific Power BI Workbook to be taken out and published, allowing it to be re-used by other consumers. So rather than having duplicated logic hidden in Power BI workbooks you can simple build once and reuse many times.

This sounds awesome, I hear you cry. Why do I need anything else? Why can’t I just use Power BI end to end and be done with it? Let me dump my cumbersome data warehouse and just build the entire thing in Power BI.
Can I do that?
Well, in some cases, yes you can. But in others, I would stay probably stay away from it.
For team and departmental BI, Power BI Dataflows is a fantastic addition. No longer do you need to invest in a complex ETL and data warehouse build or conversely, be stuck in manual data manipulation hell using hand cranked SQL Code, Excel Vlookups and other time consuming and error-prone activities. Dataflows allows you to automate the data processing, centralise it, and then let the team do what adds most value, producing insights.
For complex data integration projects involving multiple teams, agile processes, automated testing and all the other components that comprise such a project, then it’s probably not best for that space. There’s no formal source control or devops integration to start with, and I’m to see how it scales to massive datasets. It’s very early in its life though so who knows where it’s going to go. It’s a powerful addition to the Power BI armoury, and I can definitely see some pure Power BI-only self contained BI solutions being created with ETL, Semantic Layer and Dashboards all build in the same platform.
3rd Party Offerings
As well as the first party options that Microsoft supply, there are also a plethora of tools available in the Azure Marketplace provided by real big hitters in the ETL space that are fully supported in Azure. This article doesn’t cover those, but for some examples check out Informatica and Datameer.
Summary
As always, there isn’t a black and white option about what tooling you should use, and often depends on several different factors including team size, skills, data source complexity and scale plus many others. Below I try and summarise where I feel each solution fits best, but over the coming weeks and months as Power BI Data Flows and the upcoming Data Factory Data Flows are picked up by more and more data developers, it’ll be interesting to see what new patterns emerge.
It’s also fair to say that you could pretty much adapt any of them to suit your needs depending on preference. The table belows some of my own opinions of what’s best for what, but feel free to experiment with each and see what works.

