**NOTE** Whilst this post refers to SQL Server 2019 Big Data Clusters, which requires signing up to the private preview, for those who don’t need the HDFS features and just want Data Virtualization with the enhanced Polybase, then get the CTP release here **
One major stand out feature of the new SQL Server 2019 (currently in CTP – Community Technical Preview) is the advent of SQL Server Big Data Clusters. This marks a major movement in SQL Server land to a territory that it hasn’t quite been to before. Essentially, with SQL Server Big Data Clusters, this plants SQL Server firmly in Data Hub territory, bringing with this many features, including –
– Data Virtualization (Subject of this blog post)
– Data Lake –
SQL Server 2019 Big Data Clusters (BDC) brings with it HDFS Storage Pools, allowing you to store big data ingested from many different sources. Once in, you can query this ingested data and combine it with your own relational data.

– Scale Out Data Mart –
SQL Server 2019 BDC allows you to store and cache data pool nodes to provide high performance querying at scale.

– Integrated AI and Machine Learning –
SQL Server 2019 BDC enables AI and machine learning tasks on the data stored in the HDFS storage pools and the data pools. You can use Spark as well as built-in AI tools in SQL Server, using R, Python, Scala, or Java.

In fact, Microsoft’s online docs spell it out much better than I can –
Starting with SQL Server 2019 preview, SQL Server big data clusters allow you to deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes. These components are running side by side to enable you to read, write, and process big data from Transact-SQL or Spark, allowing you to easily combine and analyze your high-value relational data with high-volume big data.
— SQL Server 2019 Big Data Clusters
Introducing Polybase and Data Virtualization
In SQL Server 2019, the existing Polybase engine (a SQL-on-files engine that allowed users to connect to data in big data stores like Cloudera, or storage platforms like Azure Blob) has been given a massive capability injection. The end result being that it now supports the querying of many disparate data stores, such as Oracle, Mongo, Teradata and many more.
At a high level, think of SQL Server Polybase as creating a single point of querying across your data estate, and can be visualized using the diagram below –
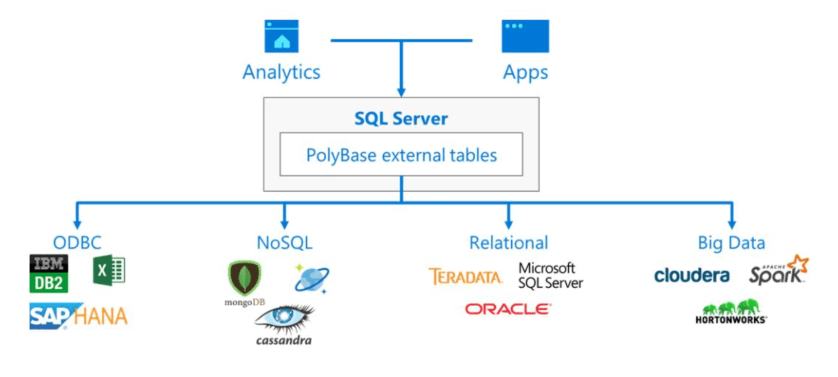
In terms of usage, you define your external data sources, the credentials to connect with and then you simply map your external tables so that they can be queried using good old T-SQL.
Once your data source and tables are defined, you write your query against the external table(s), which is in turn pushed to the target (such as Oracle), with the query being executed there. The results are then fetched back to the originating query point, such as a BI tool, SQL Server Management Studio or the new Notebook feature. This can be joined with other external sources, as well as local tables on the SQL Server instance, all within the same SELECT statement.
Why Should I Care?
Good question, pretend audience member. The reason why this is potentially really useful is many reasons, but the main one I want to discuss today is Data Virtualization.
The problem faced by many organizations today, especially those with lots of legacy applications, is that they have data silos all over the place. These can be old applications that JUST WON’T DIE through to legacy data warehouse and BI platforms that are too complicated to unravel and rebuild. Consumers need to be able to consume this data, but don’t want to build yet more data silos by moving data from these stores into yet another one.
With Data Visualization, this allows you to have one single query point from where you run your T SQL code or connect your BI tools to, join your disparate data and fetch the results. No more data movement, just a semantic layer to abstract away the complexity of your underlying estate.
For a recent customer demo, I built a SQL Server 2019 Big Data Cluster and used it to connect to and integrate data from SQL Server, Azure SQL Database, MongoDB (Using the CosmosDB Mongo API), HDFS and Oracle. Aside from a few issues installing my demo Oracle instance (Container Database vs Pluggable Database, I’m looking at you), it all worked really well.
First of all, I installed the SQL Server 2019 BDC. I did this in Azure using the Azure Kubernetes Services. There is a nice deployment script provided to help you get up and running quickly from here. Note, you will need to have signed up for the CTP to get the access details for the docker images if you’re using the Big Data Clusters.
Then, in order to setup my various data sources I essentially followed Bob Ward’s demos here – https://github.com/Microsoft/bobsql/tree/master/demos/sqlserver/polybase/
The only issue I had with the above was that the docker option for Oracle no longer seems to work, so I installed Oracle Express on an Azure virtual machine as an alternative.
I then created a simple Oracle instance and created a sample table to test –
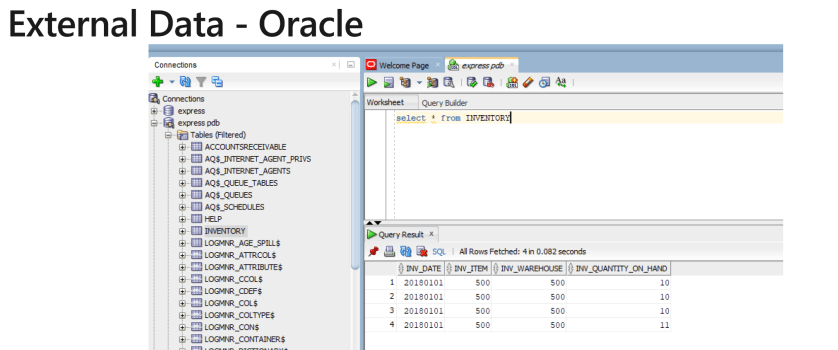
Within my SQL Server 2019 environment, I then went through the following steps –
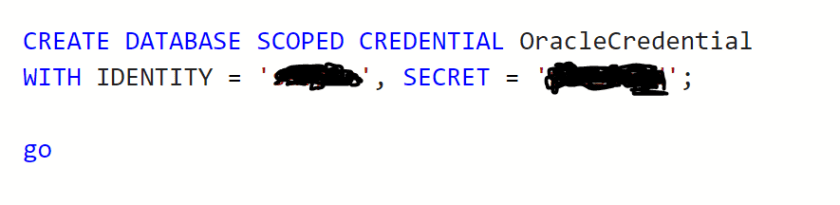
Create Database Scoped Credential
This creates the credential used to access my data source:
Create External Data Source
With the credential created, I created an External Data Source entry for my Oracle instance by providing the oracle instance IP and port. This is a one time thing for each data source, from which I can then add as many tables as I need.

Create External Table
Now the External Data Source has been added, I can now add an external table in SQL Server. This appears with “(External)” in object explorer to show that it’s pointing to a remote data source. When I issue a query, this is actually querying the table in Oracle that I setup earlier. Note, we pass the DATA_SOURCE argument to the WITH statement that contains the Data Source we created in the previous step.

Once created, I can query like any other table –

And can join to other tables as required –

And it’s as simple as that. Hopefully I’ve demonstrated the value that data virtualization can bring. Out of the box, SQL Server BDC allows you to connect to many disparate data sources as if they were all the same thing. From here you can point BI Tools or Semantic Layers such as SQL Server Analysis Services to this central data hub and make your analytic world that much more simpler.
