Azure Automated Machine Learning is an awesome tool. It significantly lowers the bar of entry for data science by allowing folk to submit their datasets to the service, tell it what type of data science task (ie Classification, Regression etc) it is, configure a couple of parameters and then – boom – the machinery will grind away, iterate through all the various algorithms and parameters until it finds the “best model” – from which you can publish as a web service endpoint to be consumed by the likes of Power BI.
See this video for an overview of the service –
So far so awesome – however, what if you need to do some batch scoring against this newly generated API to land the output in a new scored dataset? You could do Power BI and connect to the endpoint, but what if you needed proper batch scoring into another table to be consumed as part of your wider data platform?
Well – if you can dabble in code (and by that I mean the likes of Python, not SQL), then you’re golden – there are numerous notebook examples out there that shows you how to capture the best model from the AutoML run, convert it to onnx format (to allow real portability between services – key for later in this blog) and consume.
But what you don’t want to dip into code? What if you’ve got your dataset in your Synapse workspace and want a build of model off that, then use it to “score” fresh data as it comes in?
Well, the Synapse Model Scoring Wizard is what you need to be checking out along with this excellent overview video –
The Model Scoring Wizard allows you to train models via Automated ML and subsequently use said model for future batch scoring.
Let’s get started:
Prequisities
A dedicated SQL pool and a Spark Pool created in the above workspace.
An Azure Machine Learning Workspace
A service principal to with appropriate permissions on the Azure ML workspace.
Some data. I used a Kaggle dataset for used car prices for this.
Step 1 – Create a Linked Service to your Machine Learning Workspace from your Synapse Workspace.
This is so you can submit your machine learning run from Synapse
In your Synapse Workspace, click Manage, then Linked Services, then + New to add a new linked service.

Browse for Azure Machine Learning –
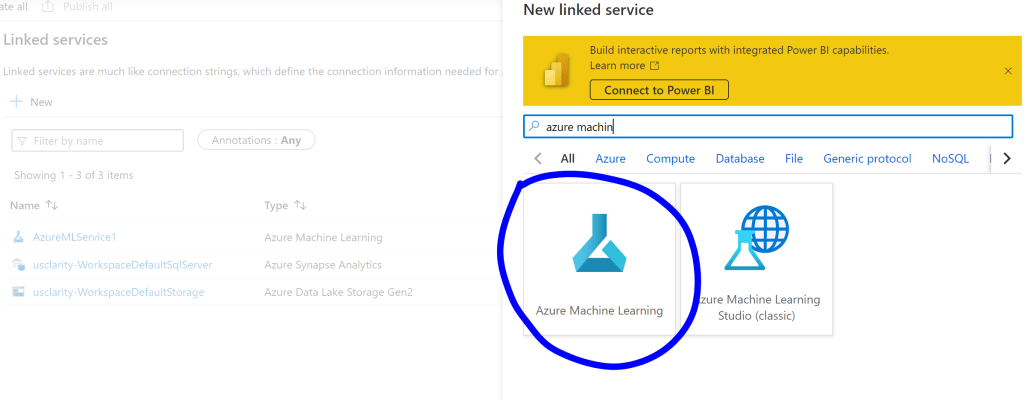
Then complete the necessary fields to add the Machine Learning Workspace you created earlier. Note, you will need the Service Principal details here too from the prereqs.

Step 2 – Train your data using AutomML, directly from the Synapse Workspace
1 – In order to train a new model, you’ll first need your data inside a Spark table. A quick way of doing this is to use the to import your data file using the “New Notebook” functionality –
2 – With your spark table imported, you can now launch the model training wizard by right clicking your newly imported table, clicking “Machine Learning”, then click “Enrich with new model” –
When setting up your run, you will need to select the Machine Learning workspace you linked to earlier, then choose the relevant options. As I was predicting car prices in this demo, I chose “regression” and changed the job time down to 1 hour.
NOTE – I also amended the ONNX model compatibility to “TRUE”, as Synapse can currently only recognise ONNX model.s.
Whilst this is running, we can flip over to our Machine Learning workspace and watch as the run iterates through the different algorithms in AutoML before ultimately finding and registering the best fit model.
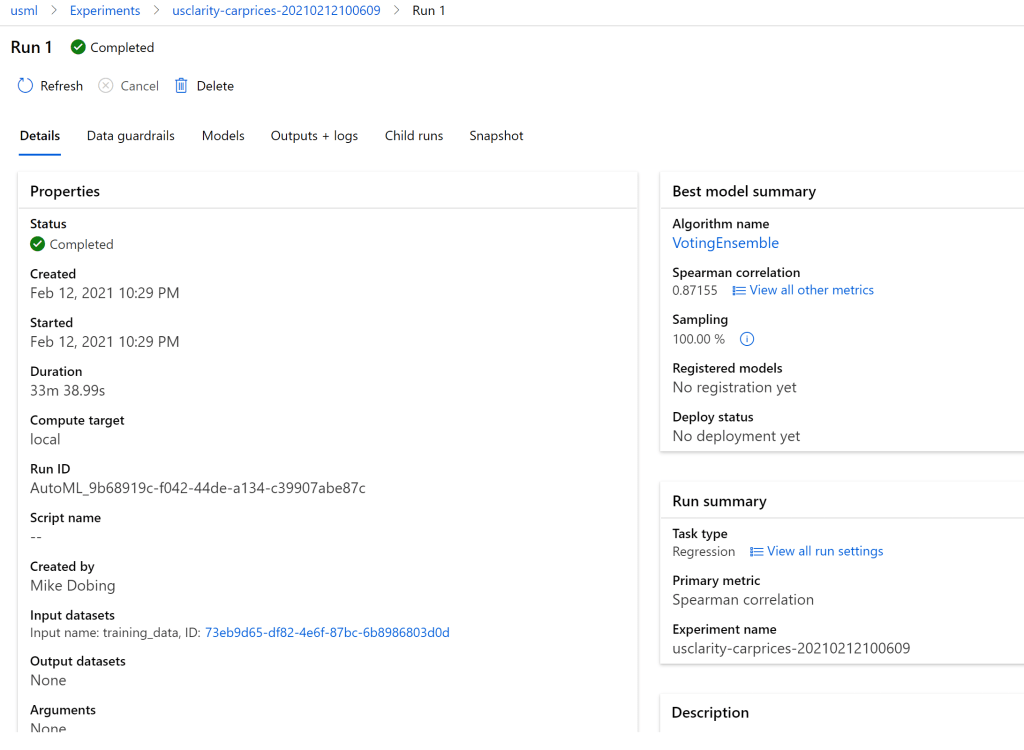
And we view the various models that were scored as part of the process –
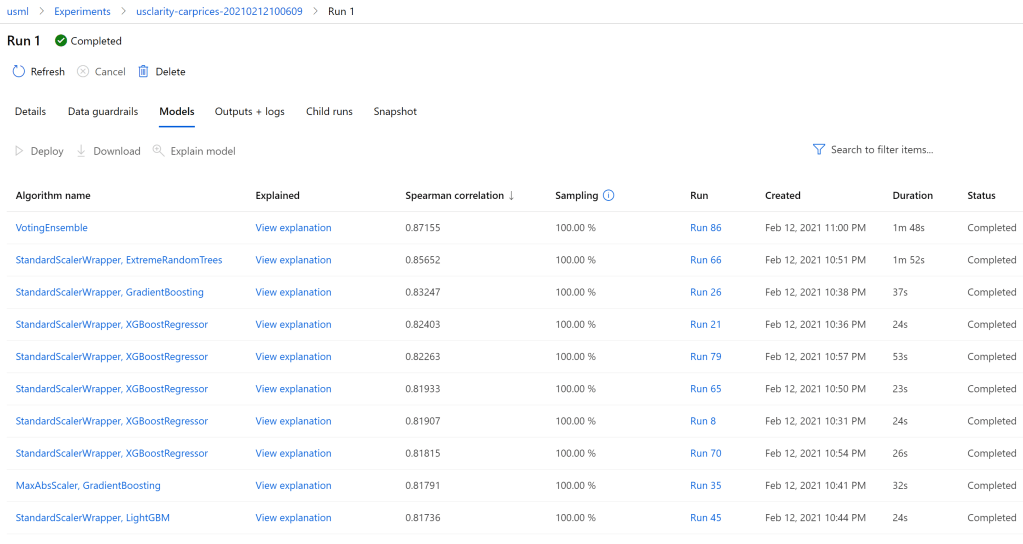
Step 3 – Create a batch scoring stored procedure from our AutoML model
Once our model training and registration is compete, we can now take some “actual” data from within our Synapse SQL Pool and enrich it with the trained model. In this example I’m simply using the training data again to simulate the process.
In your Workspace, create a table in your Dedicated SQL Pool that contains your new data. Then, right click the table, click “Machine Learning”, then click “Enrich with existing model”.
This process will do the following things –
- If a table to store our model doesn’t exist, it will allow you to create one.
- It will create a stored procedure that uses your data table, along with the imported model, to create a PREDICT statement. This creates an output dataset that includes your original fields PLUS the scored columns that are produced from the model.
- You can now use this stored procedure as part of a regular process to batch score new data against your trained AutoML model.
It will take a few minutes to upload the model into Synapse and create the DDL (data definition language) to create the stored procedure. When that’s done, it will open the final SQL script which you’ll run to deploy your scoring scored procedure.
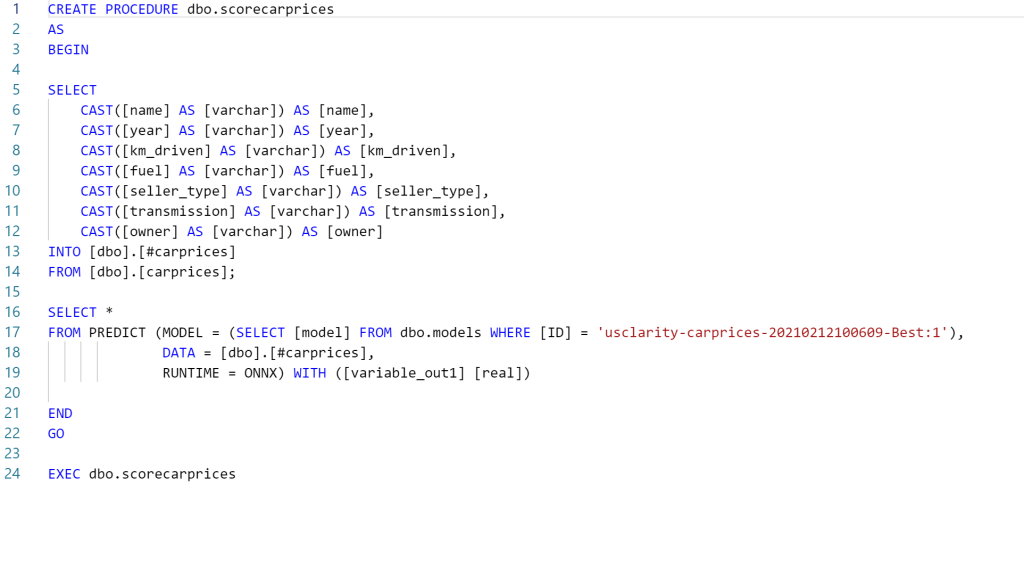
When you call your stored procedure you now get your original dataset back, plus the “scored” value from your AutoML model.
Summary
Hopefully this shows you a straight forward way of creating an AutoML model with minimal effort for your own data, training and creating the best fit model, before finally allowed an easy of scoring fresh data against your model, all within the confines of the Synapse Workspace.
