
Note – whilst I use the term Azure Data Factory in this article, the approach is supported by both Azure Data Factory AND Synapse Pipelines inside your Synapse Workspace
Pausing, Resuming, Scaling up, Scaling down. Anyone who’s spent time with Synapse Analytics (and its predecessor – Azure SQL Data Warehouse) will be familiar with these activities as you manage the compute resources of your Synapse SQL Pools.
There are various ways of automating compute management with Synapse (and in Azure in general), with the main one most likely via Azure Automation and Powershell. I myself have used Azure Logic Apps on several occasions to call various Rest APIs to automate various processes.
What folk tend to do is either call a Logic Apps end point that in terms calls the Synapse REST API, or instead use a Webhook activity attached to an Azure Runbook that runs the necessary Powershell against your target resource.
This works well, but what if you wanted to keep this processing all within Data Factory itself using “native” functionality and not have to jump to other tools for these processes?
This article will show you not only how to call these processes directly from Azure Data Factory, but also to wrap them into a kind of “Utility Pipeline” that you can reuse across other processes.
Before I explain the steps, here’s the completed pipeline –

- SetAutomationTask – This activity is used to set the variable that defines which activity the “Switch” activity does downstream. In production, this would likely be replaced by a LookUp activity that determines which automation task we want to run.
- GetBearerToken – This activity obtains a bearer token from Azure Active Directory and that authorizes the process to call the relevant REST APIs that operate the various compute management tasks.
- AutomationOptions – the magic sauce. The Switch activity (my new favourite activity) allows you to dynamically control what activities are called at runtime. The Switch activity parses an expression that determines which “case” statement is evaluated. For this helper pipeline this activity allows for the calling of Pauses, Resume, Scale and State activities, each perform a particular function.
SetAutomationTask

Fairly straight forward this. In this example I just amend the Value to represent the specific function I want the Switch activity to call. In reality, I would dynamically determine this at runtime using parameters.
GetBearerToken
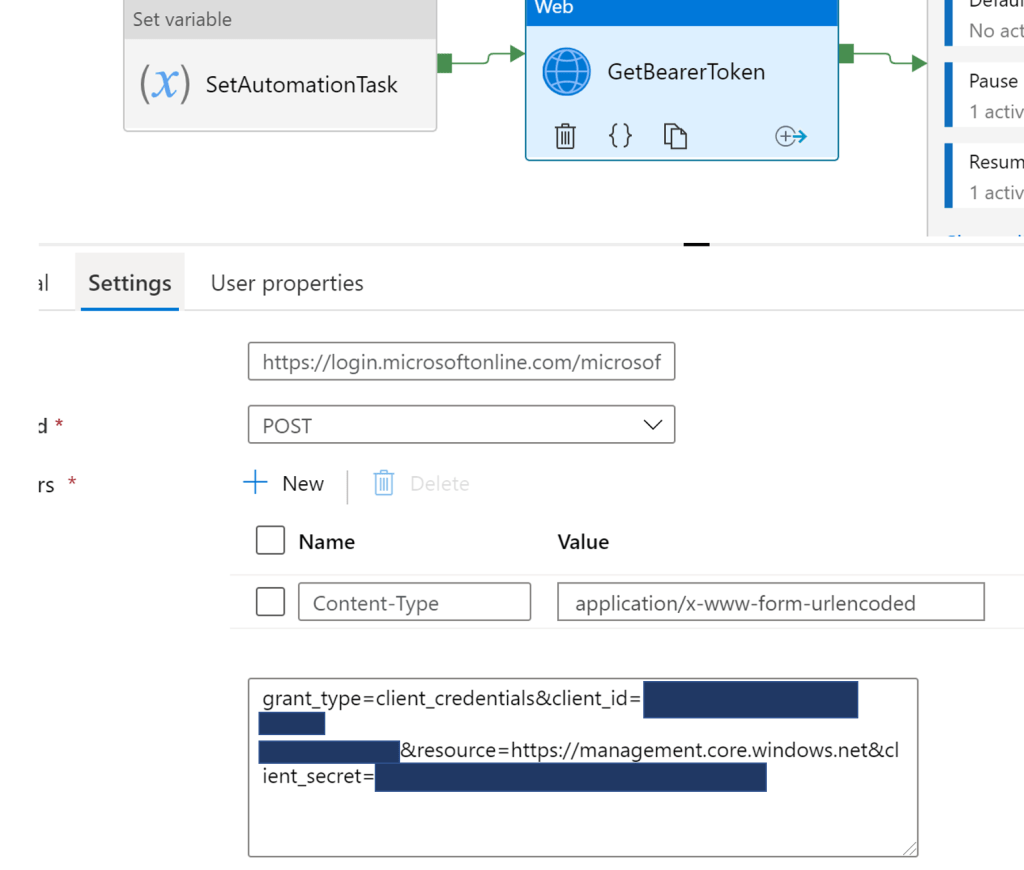
This activity simply obtains the bearer token to authenticate against the Synapse Resources. This example uses a Service Principal to make the necessary calls. See here for instructions for setting one up.
AutomationOptions
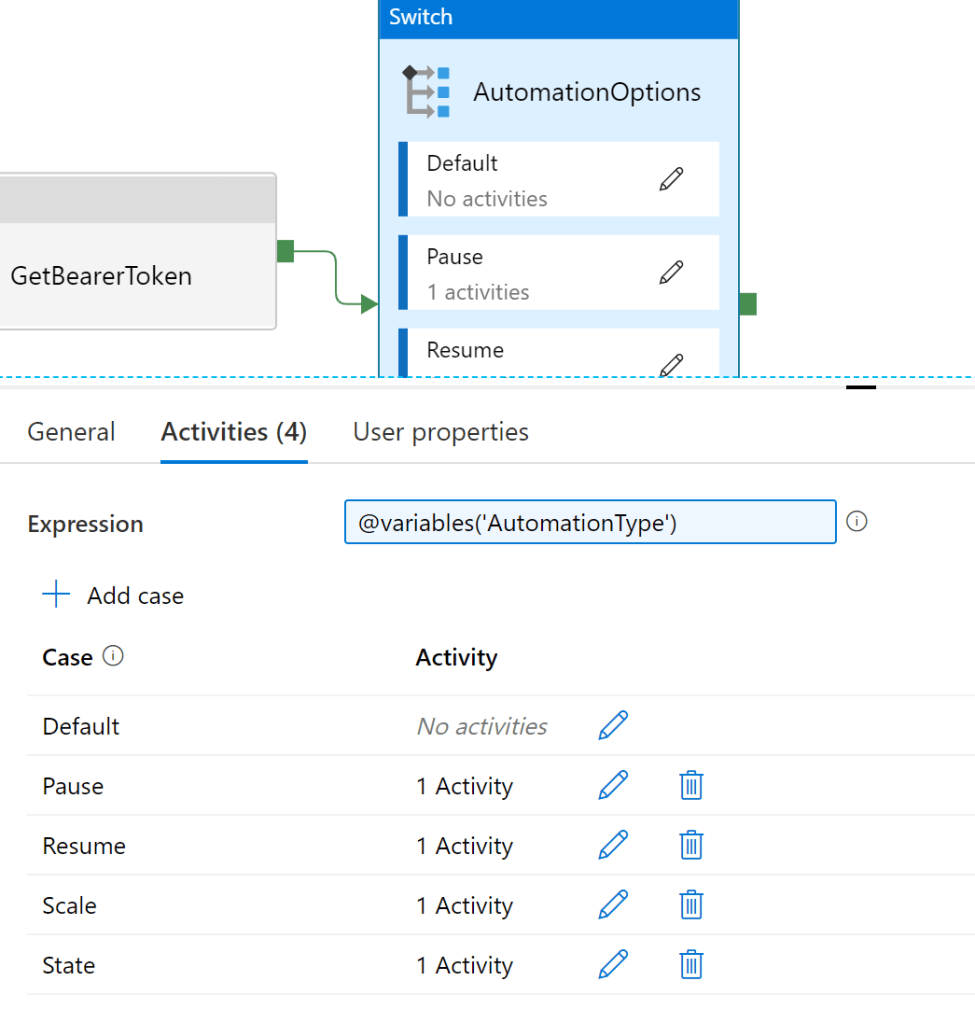
In this activity, the Switch expression evaluates the variable that was set in the “AutomationType” activity. This value is then used to determine which Case activity to call. As I set the variable to “Pause” above, it would call the activity linked to the “Pause” Case activity.
For reference, the other activities it calls are –
Resume – Resumes the SQL Pool
Scale – Scales the SQL Pool to the specified DW units.
State – Returns the state of the SQL Pool
I won’t show every activity, as once you’ve seen one you can work out the rest. But in this example it calls the “Pause” activity –

In the above diagram, we call a Web activity that is used to submit a POST to the relevant URL that triggers the pausing of our target Synapse SQL Pool. I’ve set pipeline parameters here that can be used to set the relevant resource dynamically at runtime –

@concat('https://management.azure.com/subscriptions/',pipeline().parameters.SubscriptionID,'/resourceGroups/',pipeline().parameters.Resourcegroup,'/providers/Microsoft.Synapse/workspaces/',pipeline().parameters.DWServer,'/sqlPools/',pipeline().parameters.DWDatabase,'/pause?api-version=2020-12-01')I can now can now call my utility pipeline at will, setting parameters dynamically depending on what particular activity I want to call –
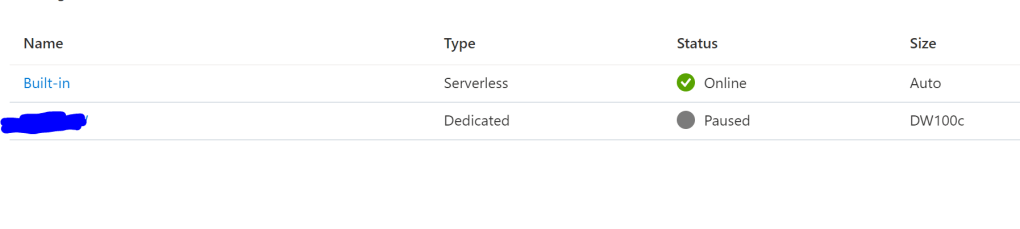

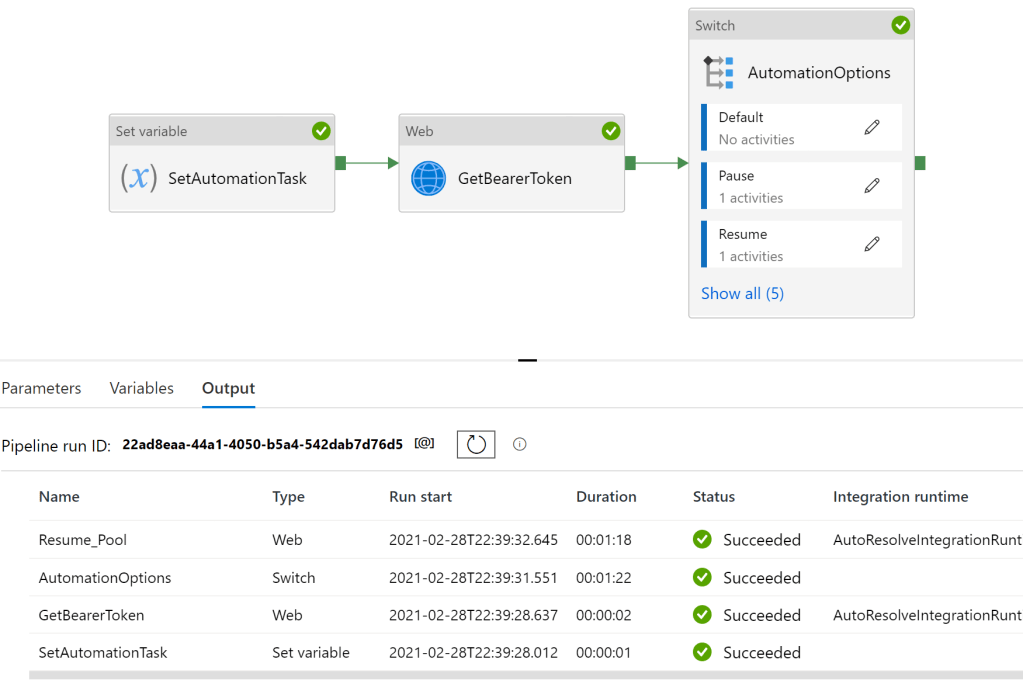
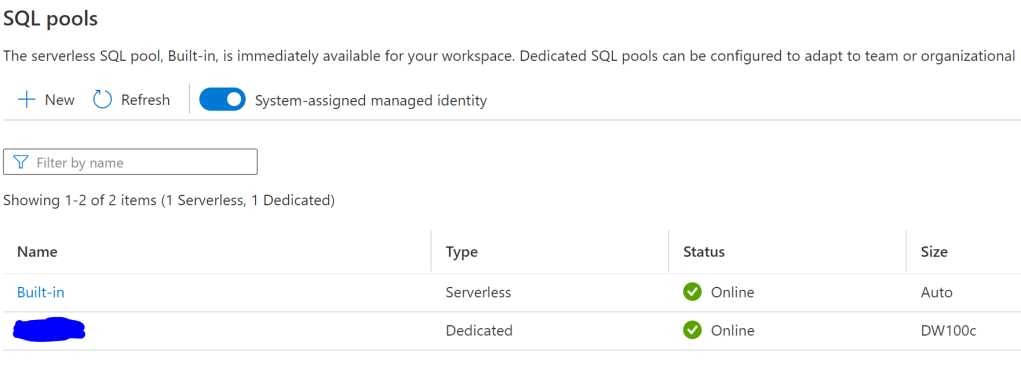
And we can see our SQL Pool has successful restarted –
Conclusion
Hopefully you can see the value of such a “Utility Pipeline” that can be reused across many others, and can also see how you can adapt the excellent Switch activity to allow for true conditional logic with your workflows. Eg, you can trigger different pipelines depending on the evaluation of an expression, in a similar way to Conditional Split tasks in SSIS.
As always, any thoughts, feedback – all welcome!
