
In a previous post I blogged about “Building the Datawarehouse-less Datewarehouse“, which is pattern I’ve always liked wherein we can build a logical star schema across a raw data lake and then query it using our reporting tools. In the previous post I focused on Power BI/Analysis Services as that querying layer, but what if we didn’t have Power BI? What if you just wanted a really agile, simple way of creating a logical data warehouse schema across your data lake that can be consumed by any tool?
That’s what this post is about, and shows an approach for building logical star schemas (other data modelling approaches do exist…) that can then present simplified structures for your analysts to build reports on or perform ad hoc queries in an agile manner WITHOUT having to go through the physical processing of the raw data.
This is where SQL Serverless, part of Synapse Analytics, enters the room. In the words of the Azure docs –
“Serverless SQL pool is a query service over the data in your data lake. It enables you to access your data through the following functionalities:
- A familiar T-SQL syntax to query data in place without the need to copy or load data into a specialized store.
- Integrated connectivity via the T-SQL interface that offers a wide range of business intelligence and ad-hoc querying tools, including the most popular drivers.”
In short, Serverless SQL allows us to create logical constructs across your data lake in the form of views or external tables, and then exposing this denormalised schema to your analysts.
Let’s use the AdventureWorks, that good old sample database as an example. In this article I’ll use the AdventureWorksLT schema which is a cut down version of the full one, but more than sufficient to explain the concept.
Please see schema below (the current version is slightly different, but this is close enough), courtesy of dba.dyicentre.com
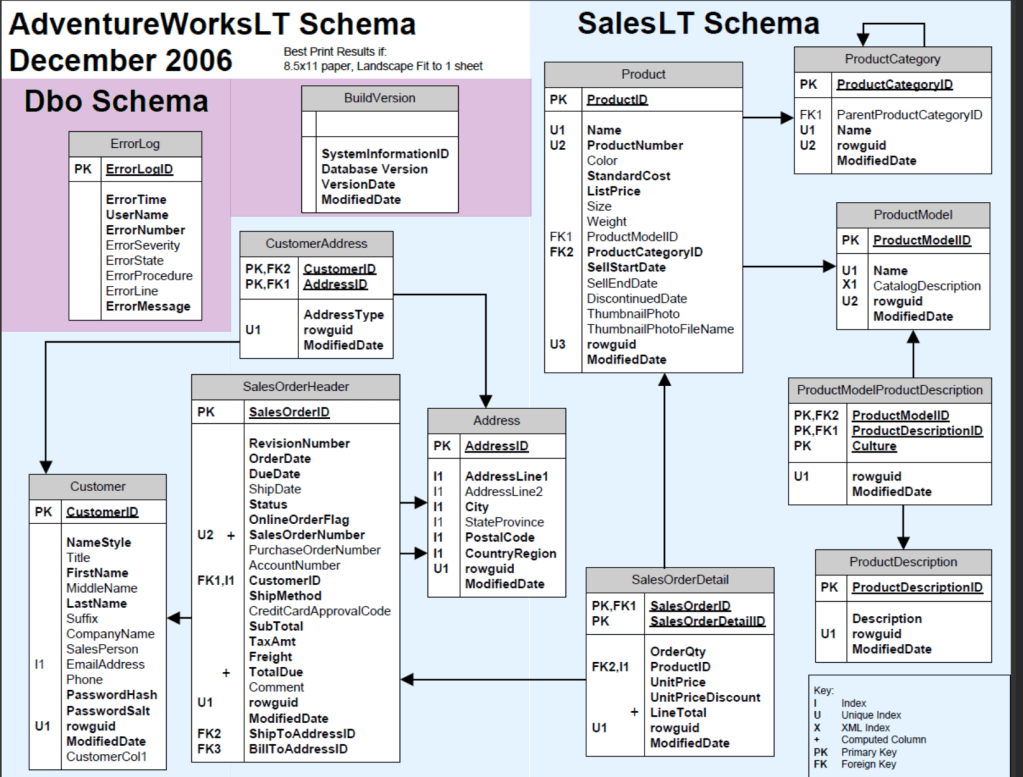
Whilst the schema above isn’t overly complicated, you can see from a dimensional approach that this could be heavily simplified to ease reporting into a star schema such as this –
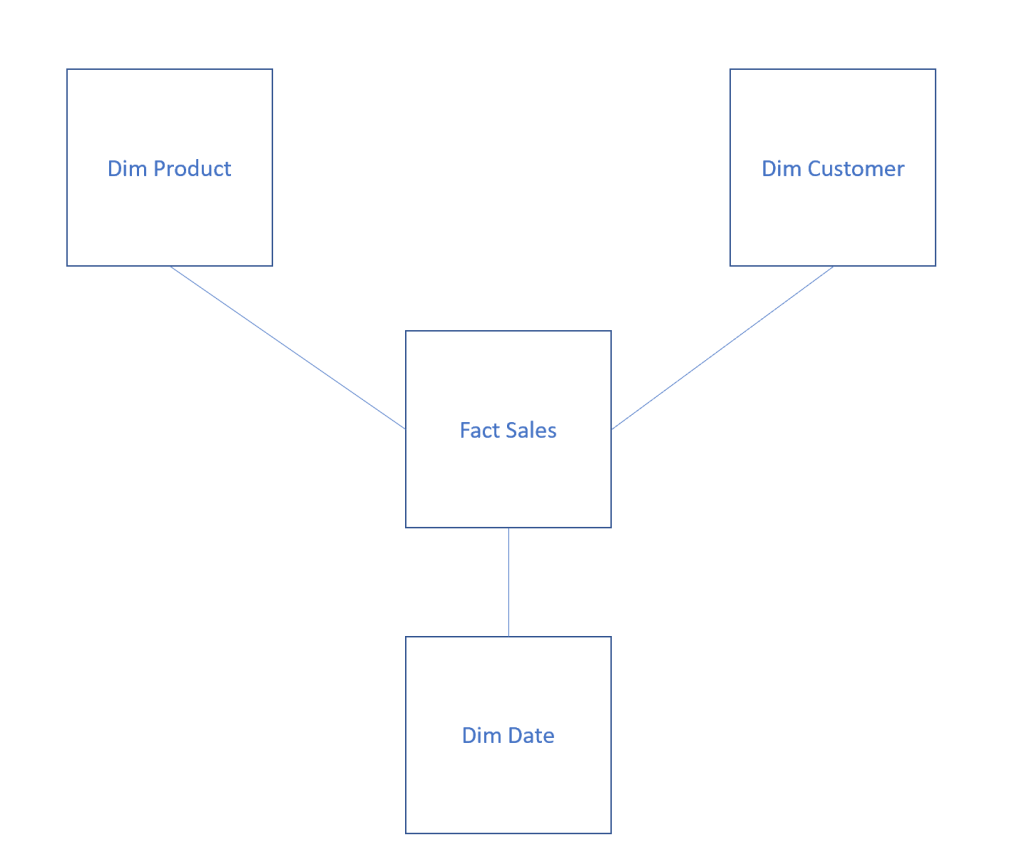
Serverless SQL Pools let us apply this transformation without having to do any kind of physical data processing. Simply land your data in the data lake, apply the virtual “views” on top that abstract away the underlying complexity, and you’re away.
Let’s take Dim Product as an example. This is produced from the following tables –
- Product
- ProductModel
- ProductCategory
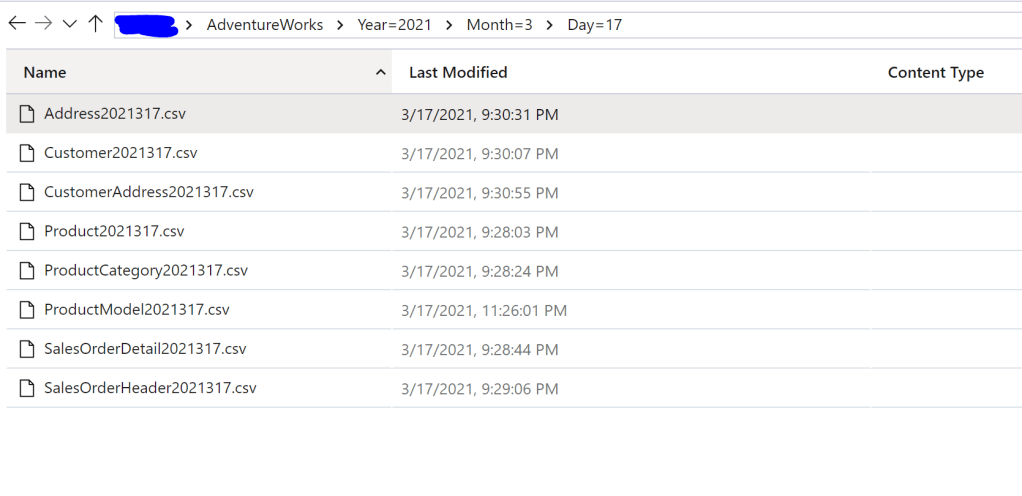
In our environment, we will have already landed our AdventureWorks data in our data lake in their raw/native format using integration tools such as Synapse Pipelines or Azure Data Factory.
In this example I’ve landed them all as .csv files in the root of my data lake, but in a “proper” environment you’d likely store these as parquet files in partitioned folders to improve performance at larger volumes. But for now, we have this –
If you haven’t used Serverless SQL before, you can very easily query the file in the data lake using standard SQL –
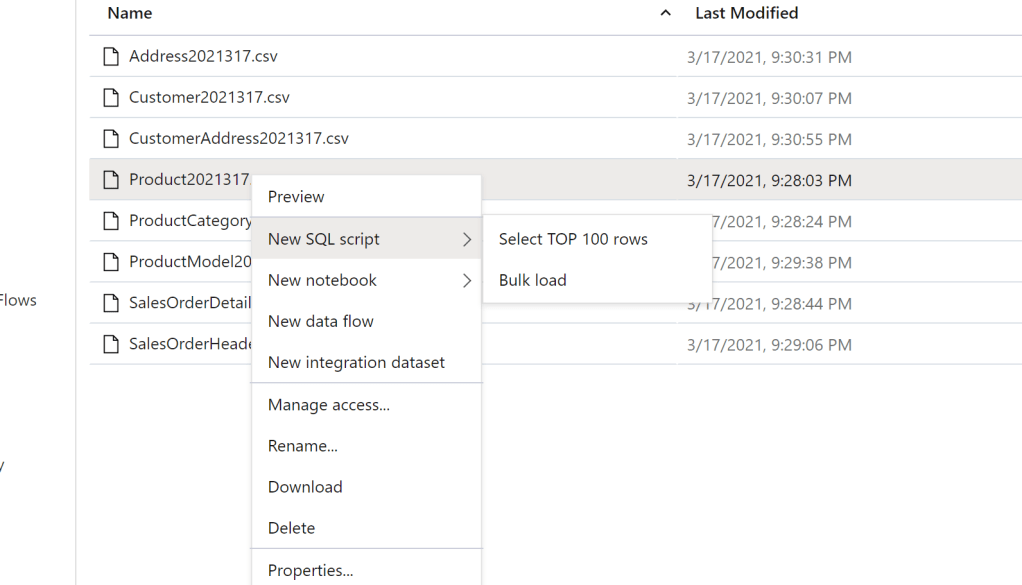
Which returns SQL code to query our file –
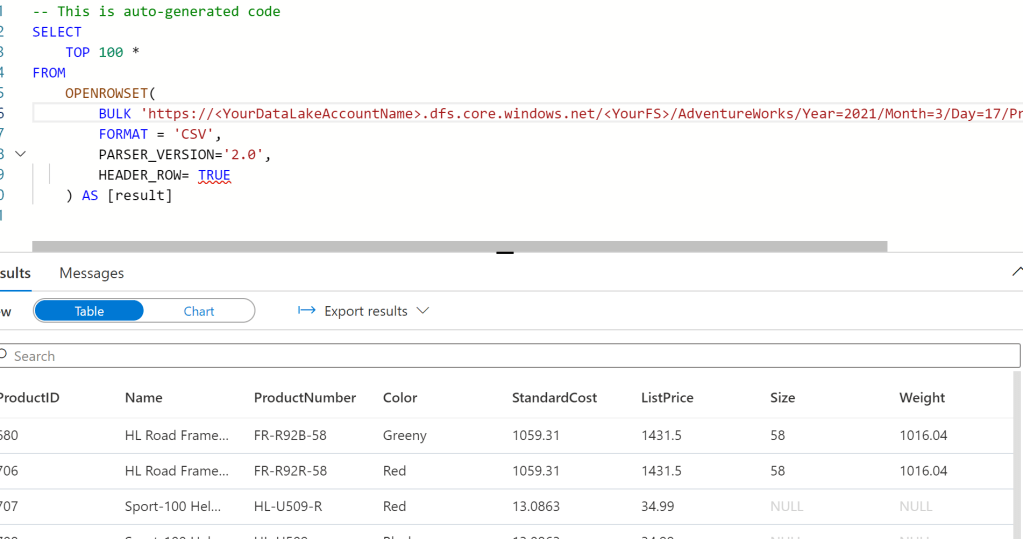
In order to create our logical Dim Product view, we first need to create a view on top of our data files, and then join them together –
1 – Create a view on our source files. Repeat this for each of our source files (Product, ProductModel & ProductCategory). Below is an example for the vProduct view of the Product.csv file. Note, whilst this is a basic SELECT statement, you will apply any specific lightweight transformations here, such as replacing NULLs with default strings, for example.
CREATE VIEW vProduct AS
SELECT
ProductID,
Name,
ProductNumber,
Color,
StandardCost,
ListPrice,
Size,
Weight
,
ProductCategoryID,
ProductModelID,
SellStartDate,
SellEndDate,
DiscontinuedDate
FROM
OPENROWSET(
BULK 'https://<YourDataLakeAccountName>.dfs.core.windows.net/<FileSystem>/AdventureWorks/Year=2021/Month=3/Day=17/Product2021317.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW= TRUE,
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n',
ESCAPECHAR = '\\',
FIELDQUOTE = '"'
) as rOnce created, this allows us to query as a normal view –
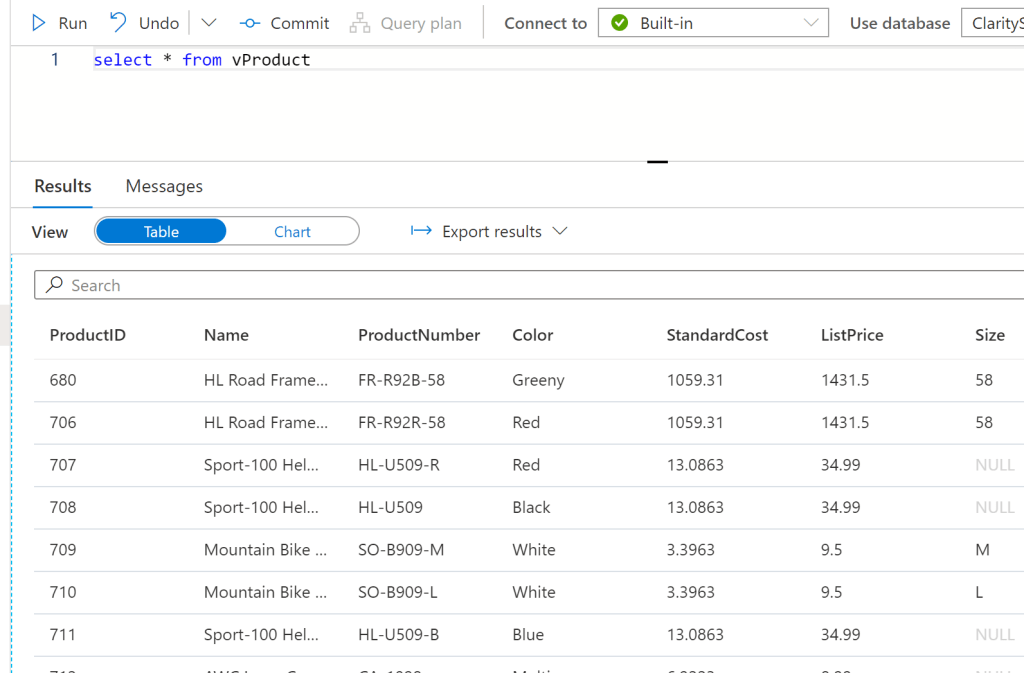
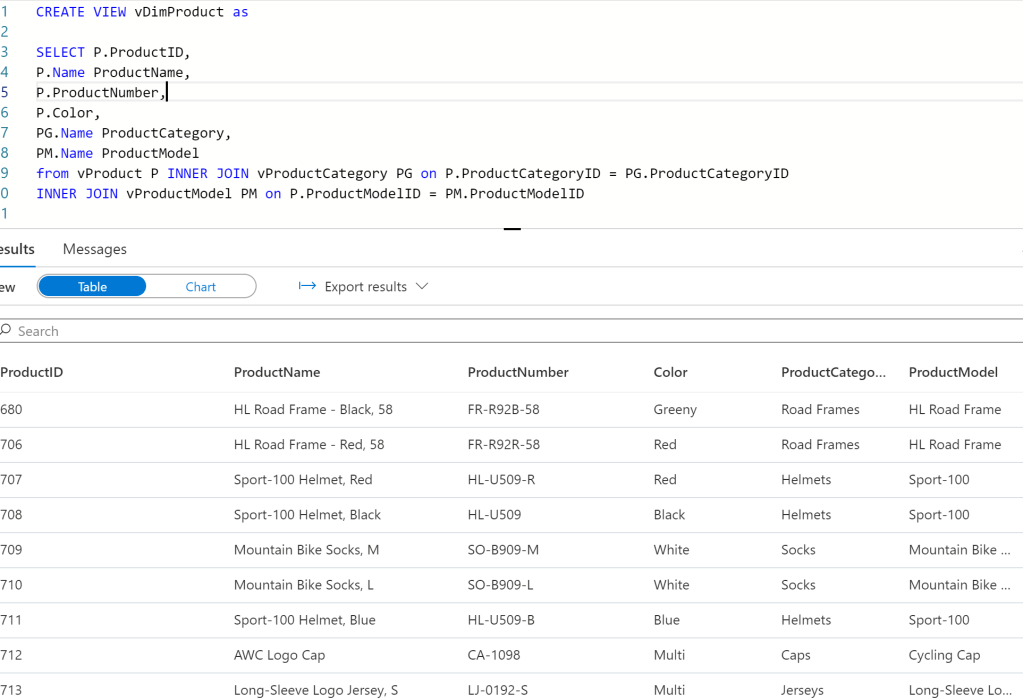
2 – Once you’ve created your source file views, you can now create a view for our Dim Product dimension by joining these together –
CREATE VIEW vDimProduct as
SELECT P.ProductID,
P.Name ProductName,
P.ProductNumber,
P.Color,
PG.Name ProductCategory,
PM.Name ProductModel
from vProduct P INNER JOIN vProductCategory PG on P.ProductCategoryID = PG.ProductCategoryID
INNER JOIN vProductModel PM on P.ProductModelID = PM.ProductModelID
Which creates our logical dimension – vDimProduct –
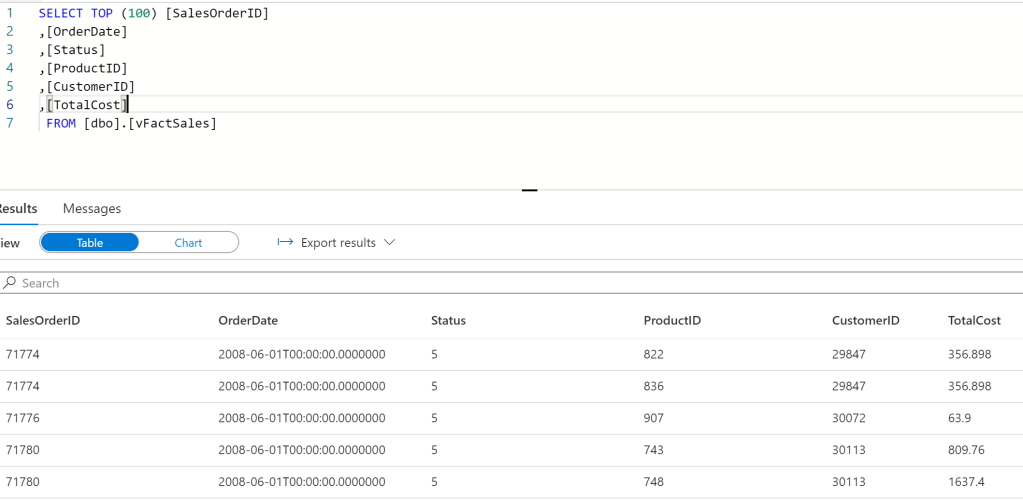
3 – Repeat this for the other dimensions and our fact. The example below is the code for Fact Sales view –
Create view vFactSales as
SELECT S.SalesOrderID,
S.OrderDate,
S.Status,
SD.ProductID,
S.CustomerID,
SUM(SD.LineTotal) TotalCost
from vSalesOrderHeader S INNER JOIN vSalesOrderDetail SD on S.SalesOrderID = SD.SalesOrderID
GROUP BY
S.SalesOrderID,
S.OrderDate,
S.Status,
SD.ProductID,
S.CustomerID
Which returns our “fact” data (metrics we wish to add up/aggregate etc). Note, I’ve included the ProductID and CustomerID fields to allow us to join to the previously created dimension views for Product and Customer respectively –
4 – With our logical Data Warehouse constructed, we can now query our report-friendly schema using Power BI or other tools –

And finally, a sample report from our logical data warehouse –
Summary
Whilst creating a logical datawarehouse like this isn’t ideal for every situation, such as those where you need more “Enterprise” DW design contructs such as surrogate keys, slowly changing dimensions or if more physical processing is needed to get the data into a usable format. But, if you need to create a reporting layer in an agile manner then creating a logical star schema in this way is an excellent, low-cost approach.

Hey nice tutorial! I have a question how do I can organize the data lake like you?
LikeLike
Hi Mario, in a production scenario I’d look to land data in my data lake normally partitioned by data, something like this system/year/month/day/file. Then in this approach use views in Serverless to present it users in a reportable way, such as dims and facts.
With the recent release of Delta support for serverless it opens up an even more robust way of doing the Data Lakehouse pattern which I’ll blog about soon.
If you need to do physical transformations in Serverless then use CETAS (Create External Table as Select) to create performant derived tables to remove the number of joins you do.
LikeLike
You are a fountain of knowledge Mike, thanks for sharing such great articles!
LikeLike