I like a good pattern. I also like a good framework. From a data perspective, nothing lends itself better to having both of these as ETL/ELT.
For those not familiar with the terms – they mean Extract, Transform & Load AND Extract, Load and Transform respectively. A minor change in wording, but a significant one.
This article today is an exploration of the various patterns I’ve seen “out there”. It’s not meant to be exhaustive, and by no means formal, but hopefully will provide insights into the varying approaches to data integration with modern, cloud-based data warehouses.
Firstly though, what is ETL/ELT?
Extract, Transform & Load (ETL) –
Extract, transform, and load (ETL) is a data pipeline used to collect data from various sources, transform the data according to business rules, and load it into a destination data store. The transformation work in ETL takes place in a specialized engine, and often involves using staging tables to temporarily hold data as it is being transformed and ultimately loaded to its destination.
Azure Data Architecture Guide Extract, transform, and load (ETL) – Azure Architecture Center | Microsoft Docs

Extract, Load & Transform (ELT)
Extract, load, and transform (ELT) differs from ETL solely in where the transformation takes place. In the ELT pipeline, the transformation occurs in the target data store. Instead of using a separate transformation engine, the processing capabilities of the target data store are used to transform data. This simplifies the architecture by removing the transformation engine from the pipeline. Another benefit to this approach is that scaling the target data store also scales the ELT pipeline performance. However, ELT only works well when the target system is powerful enough to transform the data efficiently.
Azure Data Architecture Guide Extract, transform, and load (ETL) – Azure Architecture Center | Microsoft Docs
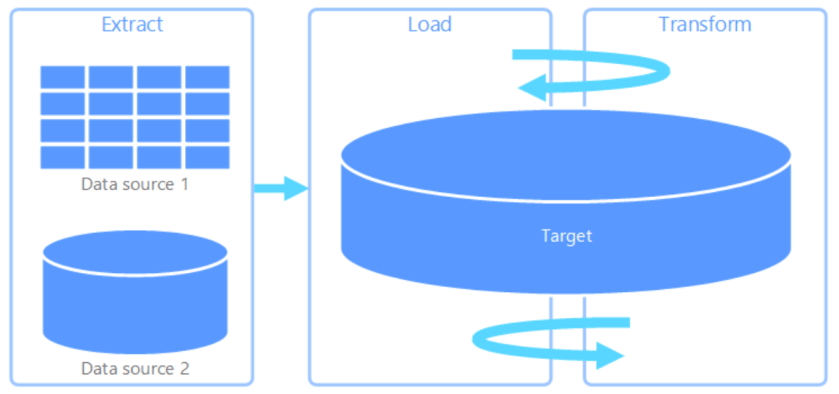
In principal, this is a fairly straight forward concept to understand, but in reality there are nuances that create subpatterns of the above, specifically ELT, that are useful to explore in order to help you make the right decisions about your deployments.
Before I dive in, the exploration of these patterns will adhere to the following rules for simplicity –
- Will focus on Azure from a technology perspective, primarily around the Synapse Analytics stack
- Will focus on batch processes, not streaming
- Will provide suggested tooling choices for said pattern
Pattern 1 – Traditional ETL
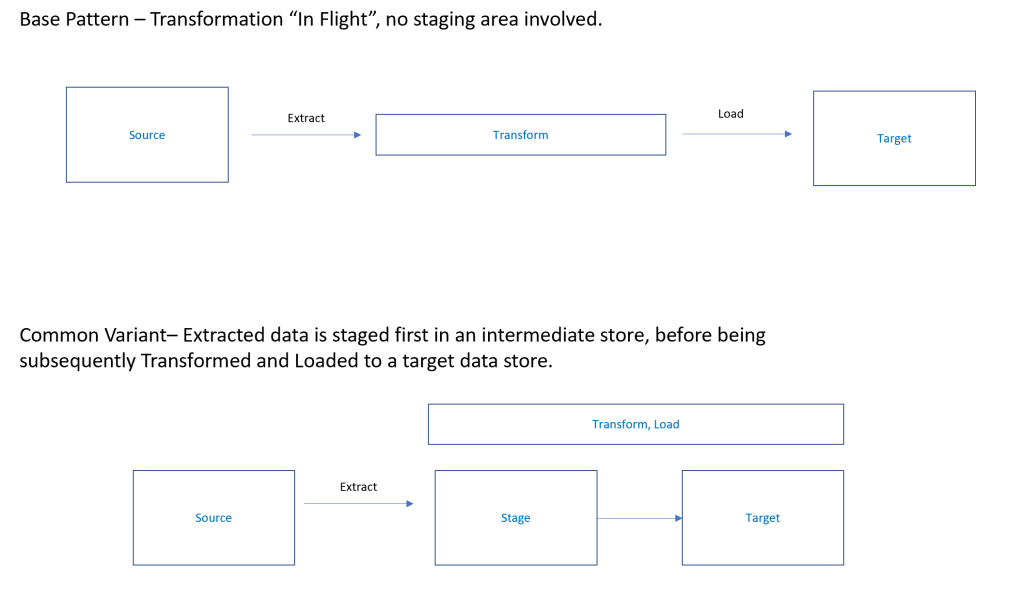
In this pattern – the traditional ETL pattern that has been around for decades – data is first extracted from line of business systems and files, such as SQL Server, PostgreSQL through to csv and text files. This extraction, and subsequent transformations, are often done using an ETL tool such as SQL Server Integration Services.
Extract & Transform
Data volumes in this pattern generally don’t tend to be “big data” and often fall into the GB – TB range in size. In this ETL pattern there is typically no “data lake” but instead extracted data is transformed “in flight” by the aforementioned ETL Tool. As the data volumes are relatively light, it allows the transformation to take place in memory inside the ETL engine itself, rather than having to push down compute to a specific data store and processing engine.
Load
The transformed data is landed in a target database schema, such as an Azure SQL Database, often modelled in a star schema to allow cleaned, curated data to be presented to your reporting tools.
You may also see a semantic layer on top of your reporting schema, such as Azure Analysis Services or Power BI. Such a semantic layer allows for querying logic to be abstracted away from business consumers, who, rather than writing SQL to create reports, they simply consume your semantic model and create reports with a drag and drop style interface.
A common implementation variant of this includes the use of a staging area, often as an untyped “staging” schema in our target data store. This allows for the creation of an elegant restart point in the event of failure, and prevents overloading the source systems.
This pattern has been around for many, many years, and, despite the rise of “modern” patterns such as Data Lakes and Data Lakehouses, this ETL pattern is still perfectly fine for many analytic implementations.
This leads us on to…
Pattern 2 – Extract, Load & Transform (Cloud Data Warehouse Variant)

Extract & Load
In this pattern, which is common in modern cloud data warehouse implementations as the data volumes (Many TBs and above) are much larger, we forgo using an in-flight transformation engine due to the fact it would be too memory-intensive and costly to transform as part of the ingestion process. Instead, we first Extract the data to the target data store (which will also serve as the transformation engine to process your data into its final structures). This approach removes load from source systems and allows an elegant restart point for down stream processing in the event of failure.
Transform
With the data loaded into the target data store, which is typically a cloud data warehouse such as Azure Synapse Dedicated SQL Pools, we then Transform the data in situ, leveraging the massively parallel processing capabilities of the cloud data warehouse. This allows for the creation of star schemas, summary datasets and any other analytical result that’s needed.
The main takeaway of this version ETL (and is common with all the other ELT variants) is where the transformation takes place. Rather than doing it in flight with the ETL tool, data is instead processed by the target data store after the extraction data has landed. This pattern has evolved due to the fact these MPP (Massively Parallel Processing) cloud data warehouses such as Synapse Analytics are built from the ground up to ingest and process huge volumes of data and transform it into structures fit for use by the business.
Pattern 3 – ELTL (Data Warehouse + Data Lake)

Extract & Load
In this pattern we deviate a bit from the base ETL pattern described previously. Rather than loading directly into a target Data Warehouse we first Extract the data into a raw zone inside a data lake. This follows the “schema-on-read” approach where we simply focus on landing the data in its raw format in the data lake with no processing to begin with. The data is untouched, it simply is Loaded into the data lake as a file exactly how it came out of the source system. Unlike the previous pattern, you don’t have to worry about the target schema when writing to the data lake (this schema enforced ingestion is know as “schema on write” where the schema must be defined up front). Instead, you simply write the data in its native format and consume directly with the relevant processing tools.
Transform
Once landed the data is Transformed within the data lake using a processing engine of some sort. Commonly in Azure, this will be tpyicall Azure Databricks/Azure Synapse Spark – if you prefer a code-rich development experience – or with Mapping Data Flows, which provides a rich GUI for the creation of high performance data transformation pipelines. Both approaches utilize Spark under the hood to provide big data processing at any scale. These transforms will range from cleansing, parsing and general “tidy up” through to applying full production transformations for dimensions and facts.
Furthermore, with the GA of Azure Synapse Analytics, this provides a new ELT processing engine in Synapse Serverless SQL Pools. This service allows you to write T-SQL statements directly on your data lake, thus providing the ability to transform data without having to spin up any dedicated compute capacity.
Following a series of transform wherein raw data is shaped through a series of layers by your processing engine, the Production (terms vary across implementation) zone of the data lake will contain your data in its production ready form, so dimensions and facts will be in the structure you’d see in the final data warehouse, analytic datasets are cooked and ready to consume and any other analytical output served fit for use by your analysts and data scientists.
Load
The final Load of your production ready data now takes please. This involves ingesting the data into your cloud data warehouse, ready for consumption.
In terms of approach, there are few ways to do this, depending on skills sets and approaches (eg code-free vs code-rich) –
- Azure Data Factory/Synapse Pipelines
- Synapse COPY TO statement
- Polybase with T-SQL
- Polybase with SSIS
- Polybase with Azure Databricks
Typically, we tend to see a mix of the above. If you’ve built an end to end orchestration pipeline inside Data Factory, then you will probably look to have a Copy Activity within Data Factory that uses either the COPY TO statement or Polybase, whereas if you’re code-heavy with data engineering favouring spark notebooks in Databricks/Synapse Spark, then you may opt to push the data out to your cloud data warehouse that way. See here for a tutorial covering that approach.
With this final load done, your corporate reporting data is now being served from your cloud data warehouse, but you have the added luxury of having cleansed, curated datasets sat within your data lake for consumption for exploratory data analytics, machine learning and other use cases.
Pattern 4 – ELtLT (Data Warehouse + Data Lake)

Extract & Load
This pattern follows an identical approach to the previous (Pattern 3) pattern in so far as we extract data in its raw format INTO our data lake “raw” zone. See previous section for further details.
transform (small “t”)
The main distinction in this pattern from (3) comes in the transformation phase. In this approach, we apply some light cleansing and transforms to the raw data but nothing more (hence the little “t”). The aim in this phase is to get rid of NULLS, apply business friendly decodes, derived columns etc. When the data is transformed into the Clean zone, the files typically match the Raw zone as a 1:1 ratio, but with the cleansing transforms making these raw data sets now cleaned and curated.
Load
These cleaned datasets are now Loaded into staging tables within our cloud data warehouse. This uses one of the methods defined in (3), but is typically a COPY TO/Polybase approach as this allows the full data ingestion capability of the MPP platform to be used and maximise that ingest throughput.
Transform
Once loaded into the staging tables, you then apply your transformation logic directly within the Synapse Dedicated Pool. This again allows the full power of the MPP engine to be used as you create/load your enterprise data warehouse star schemas within the Dedicated Pool.
Pattern 5 (ELT – Data Lakehouse)
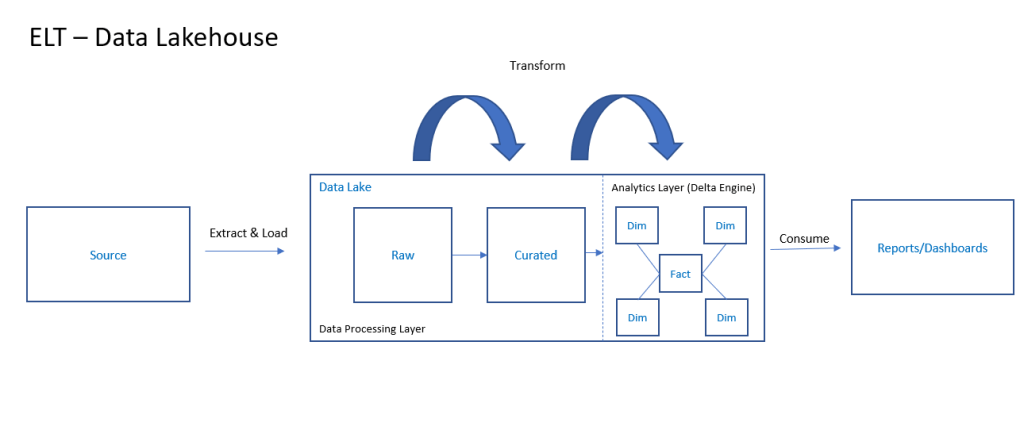
This pattern, known commonly as the Data Lakehouse approach, seeks to unify the approaches of 2, 3 and 4 together in order to remove the need to have two distinct architectures co-existing (Data Warehouse and Data Lake). This former approach introduces complexity in design that the Data Lakehouse approach seeks to remove.
In short, with the Data Lakehouse pattern there is no separate data lake and data warehouse. Instead, the data lake IS the data warehouse and vice versa.
How is this made possible? In essence, the data lakehouse brings specific technology enhancements on top of the data lake that provide features such as a high performance SQL analytics engine, ACID compliance transactions and a robust schema model that can serve both data warehousing workloads AND ML/Advanced analytics workloads, all from the same platform.
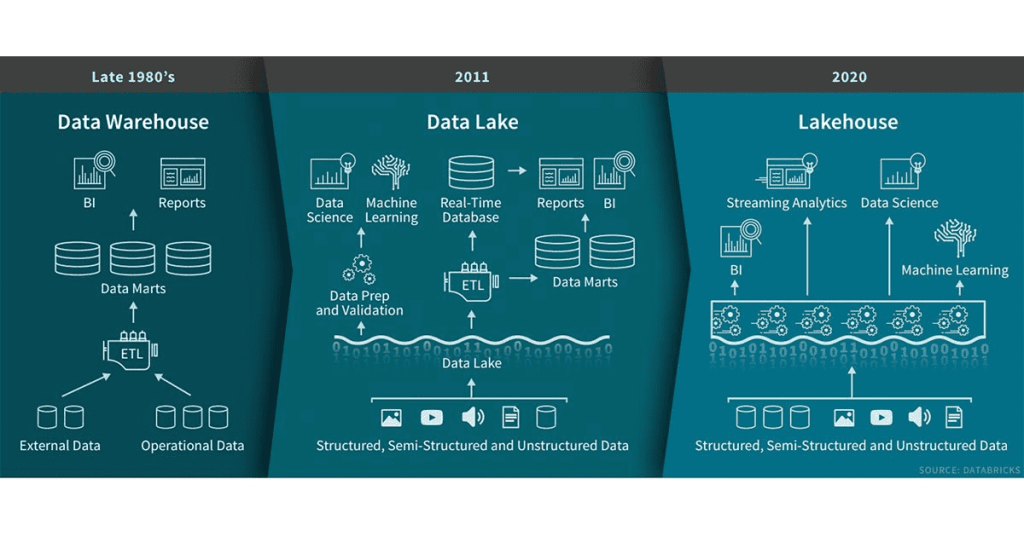
The data lakehouse pattern utilises key components of Spark, notable the Delta Engine and Delta Lake, to deliver the following ( What is a Lakehouse? – The Databricks Blog) –
- Transaction support: In an enterprise lakehouse many data pipelines will often be reading and writing data concurrently. Support for ACID transactions ensures consistency as multiple parties concurrently read or write data, typically using SQL.
- Schema enforcement and governance: The Lakehouse should have a way to support schema enforcement and evolution, supporting DW schema architectures such as star/snowflake-schemas. The system should be able to reason about data integrity, and it should have robust governance and auditing mechanisms.
- BI support: Lakehouses enable using BI tools directly on the source data. This reduces staleness and improves recency, reduces latency, and lowers the cost of having to operationalize two copies of the data in both a data lake and a warehouse.
- Storage is decoupled from compute: In practice this means storage and compute use separate clusters, thus these systems are able to scale to many more concurrent users and larger data sizes. Some modern data warehouses also have this property.
- Openness: The storage formats they use are open and standardized, such as Parquet, and they provide an API so a variety of tools and engines, including machine learning and Python/R libraries, can efficiently access the data directly.
- Support for diverse data types ranging from unstructured to structured data: The lakehouse can be used to store, refine, analyze, and access data types needed for many new data applications, including images, video, audio, semi-structured data, and text.
- Support for diverse workloads: including data science, machine learning, and SQL and analytics. Multiple tools might be needed to support all these workloads but they all rely on the same data repository.
- End-to-end streaming: Real-time reports are the norm in many enterprises. Support for streaming eliminates the need for separate systems dedicated to serving real-time data applications.
Ultimately, it’s the structured analytic layer that is the magic sauce that differentiates the Data Lakehouse pattern from others. This magic sauce is based on the Delta Lake featureset that is present in Azure Synapse Spark and Azure Databricks, and delivers the components described above.
For extra details on the data lakehouse pattern, check out the links at the end of this article.
Pattern Summary
| Pattern | Key Themes | Typical Services | When To Use? |
| Pattern 1 – ETL | Small/Medium DWs – transforms typically happen “in flight” inside ETL tool | Azure SQL Database, SQL Server Integration Services, Azure Data Factory | Small/Medium Typically < 1TB in volumes |
| Pattern 2 – ELT (Data Warehouse) | Transformation takes place in cloud DW using SQL and MPP power | Synapse Analytics (Dedicated Pools), Azure Data Factory, T-SQL | Want to do all processing inside corporate DW, no business case for data lake |
| Pattern 3 – ELTL (Data Warehouse + Data Lake | Land into data lake as raw, use processing engine (Mapping Data Flows, Spark or Serverless SQL Pools) to transform | Synapse Dedicated Pools, Azure Data Lake, Data Factory, Mapping Data Flows/Spark/Serverless SQL | When you have business cases that span reporting, ML, advanced analytics – across many disparate data sources. Big data volumes (TB – PB – EB scale) |
| Pattern 4 – ELtLT (Data Warehouse + Data Lake) | Land into data lake as raw, light cleansing and fixing using processing engine. Load to cloud DW for heavy transformations such as dimensions and fact loading | Synapse Dedicated Pools, Azure Data Lake, Data Factory, Mapping Data Flows/Spark/Serverless SQL | When you have business cases that span reporting, ML, advanced analytics – across many disparate data sources BUT favour SQL based loading. Big data volumes (TB – PB – EB scale) |
| Pattern 5 – ELT (Data Lakehouse) | All ingestion, transforming and serving takes place in the data lake (the data lake IS the DW). Delta Lake layer providers structured analytic schema to provide high performant serving layer | Azure Databricks, Synapse Spark | When you have business cases that span reporting, ML, advanced analytics but want it all within one architecture. You will have goodDatabricks/Spark skills in house and want to reduce overall complexity. |
Summary
I hope you’ve enjoyed my little tour of some of the different patterns present in modern ETL/ELT. I don’t prescribe any pattern over another – each has its own merits and use cases. You should evaluate each and see what’s a best bit for your organisation based on such things as data types/volumes, inherent skillsets, speed of ingestion and, most importantly, user requirements.
As always, any thoughts, issues, questions – drop me a line!
Useful Links
ETL/ELT Patterns – Azure Architecture Centre
Data Loading Strategies for Dedicated SQL Pool in Azure Synapse Analytics
Realizing the Vision of the Data Warehouse
The Data Lakehouse – Dismantling the Hype
Lakehouse: A New Generation of Open Platforms that Unify
Data Warehousing and Advanced Analytics

Excellent article. Well researched, a very good synthesis.
LikeLike