
I had a recent challenge from a customer that involved the need to join together datasets from different regions and present them as a unified view of data WITHOUT the data itself leaving it’s specific locality.
This meant that using something like Data Factory to ingest and transform the data was a no go as the need was for the data to remain where it was, and only the resultset to returned to the user. Instead, I turned to seeing what other approaches would work to accomplish the same task.
In the end, we settled on a solution using Power BI and composite datasets but at the same it uncovered a new approach that allowed for the unifying of data across Synapse workspaces that I hadn’t considered before, and wanted to share here.
The end goal here was to present a single endpoint that joined the underlying datasets together without the querying user being aware of where the data was coming from. Not only that, we also needed to demonstrate row level security would work in such a scenario, so that users in Country A couldn’t see data from Country B and superusers could see all data.
Serverless SQL Pools were the solution for this, and in short (for those of you who just want the base steps to take away) – we did the following –
- Created files (parquet) for the required dataset and stored them in the default data lake storage for each regional workspace
- Mapped the remote storage accounts to the consuming Synapse workspace
- Created a Serverless SQL view on top of each remote dataset. Eg, “vUSSales”
- Created a view in the consuming workspace that Unioned the different regional views together as one single view
- Applied row level security to the unioned view
- Connected to the unioned view (eg vAllSales”) that then queried all the regions at one go through the consuming/serving pools Serverless SQL endpoint.
- RLS worked as expected, meaning US users could query the view and only see US data, UK users UK etc.
The end result was a relatively simple approach that allowed a data virtualisation type solution on a single SQL endpoint, and whilst we found the Power BI approach more appropriate for this particular challenge, the actual approach described above potentially opens up other uses of Serverless SQL for people to explore. The snippet below presents a conceptual view of the approach –

How It was Done
First of all, the data files to be exposed were deposited in the required structure in the home storage accounts –
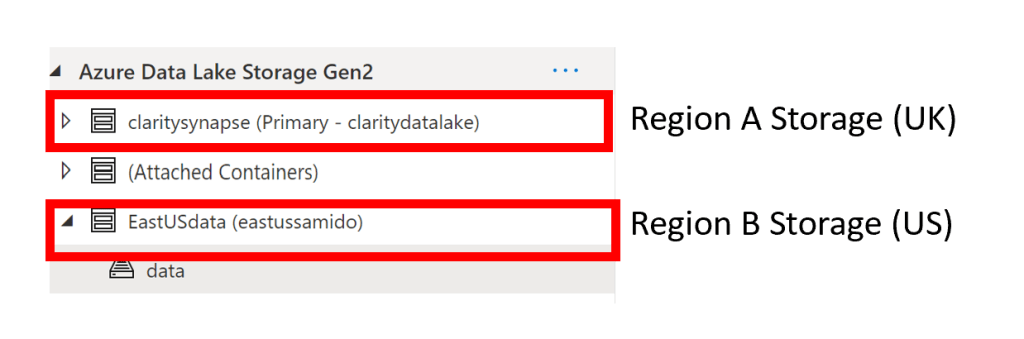
The storage accounts were then added as linked storage to the consuming Synapse workspace –
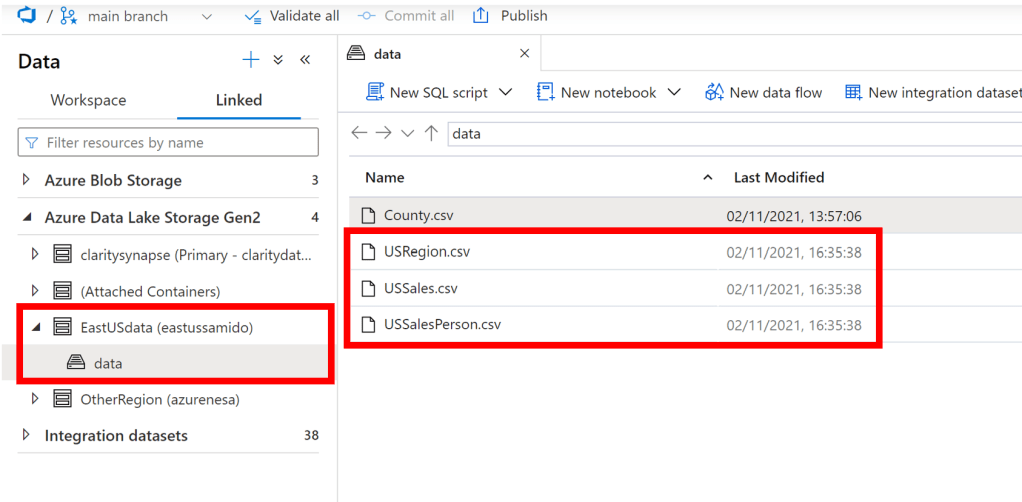
We then wrapped the files in Serverless SQL views to simplify the experience for end users –
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create view [dbo].[vUSSales]
as
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://<StorageAccount>.dfs.core.windows.net/data/USSales.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE
) AS [result]
GO
We then created our “One view to rule them all” that unioned these regional views together to create one single endpoint. We also applied a very simple RLS to prove the concept –
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [dbo].[vAllSalesRLS]
as
select * from vUKSales
Where (SUSER_SNAME() = 'xxx@microsoft.com')
union all
select * from vUSSales
Where (SUSER_SNAME() = 'yyy@microsoft.com')
GO
We then queried using Power BI in Direct Query using SSO (Single Sign On), which allowed us to leverage the RLS predicates in an elegant manner. In the two snippets below, the 1st is from an imported Power BI dataset that was used for high level aggregates, and the 2nd snippet shows how when the user navigates to the detail level data (Power BI Direct Query with SSO) it takes them to our vAllSales view and Row Level Security kicks and applies the necessary filter, all transparent to the user –
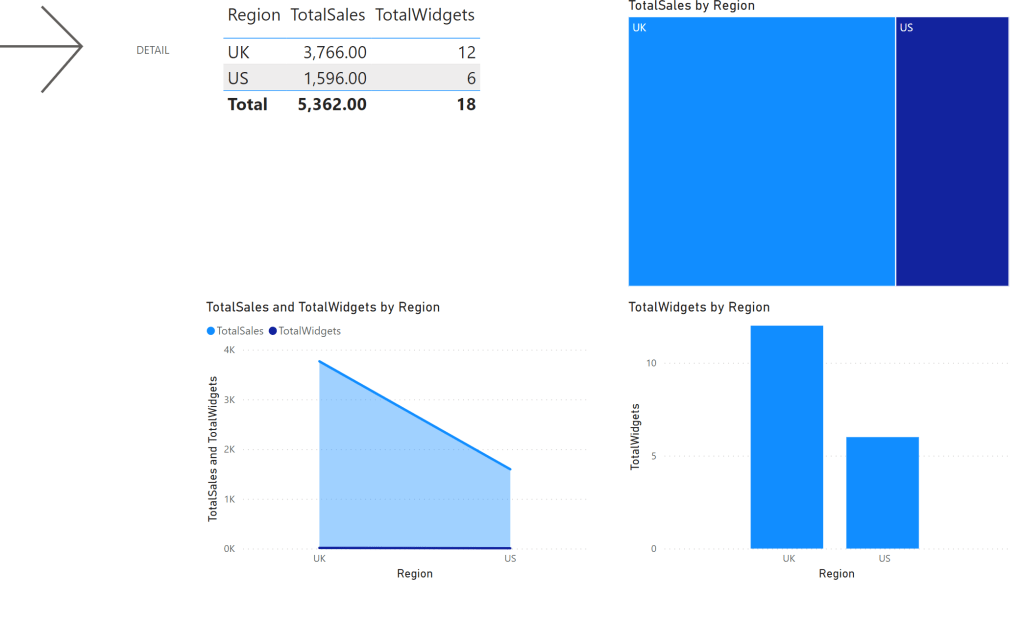
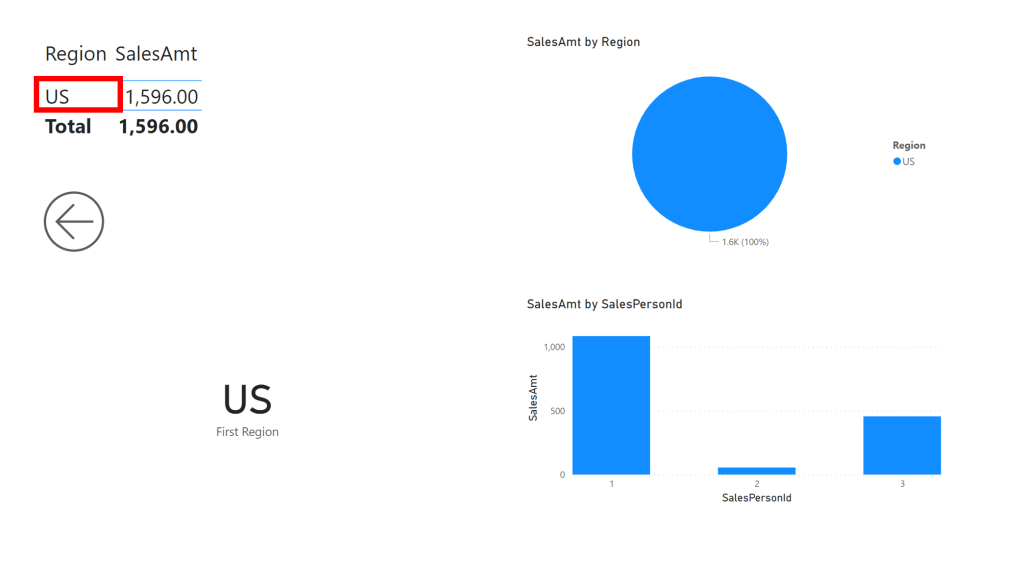
The user then sees both the high level aggregates plus the detailed data, which satisfied our “stay local” requirement.
Summary
Whilst this solution provides an elegant way of unifying datasets in realtime across disparate storage accounts in Synapse, there’s obviously a trade-off in performance, especially if you’re querying across different geographies where the laws of physics come into play. However there’s no reason you couldn’t use this for specific scenarios or either using it as a way to combine datasets into a logical view before ingesting into downstream systems.

Hi Mike, very interesting approach! I already ran into the fact that with Synapse Serverless you can add (random) storage accounts as long as the authorization is in order.
What kind of performance/latency do you experience? And what is the size of the datasets involved? Just to get a feeling on the how big this solution is.
By the way, with a very recent update since Ignite you can add multiple paths in the BULK statement. Potentially removing the underlying views? Although for debugging it is useful.
LikeLike
Hi Johannes
Thanks for the comment. I would say we experienced what I thought we would with performance – ultimately we were competing with the laws of physics and a query that spans US, Canada and the UK to return the results won’t be the quickest. In the end it was for this reason that we proposed an alternate approach using composite Power BI datasets (Import for high level, direct query for sensitive data) with a shared global dataset used in all three regions that allows a drill down to the specific Synapse pool in that particular geo.
I’ve not tried it with the multiple BULK approaches – but (and I say this without reading the docs in depth) – i think this wouldn’t be an option in our scenario as we also needed to use the RLS features of Synapse, which meant we had to have separate SQL views to apply the RLS to.
LikeLike
Finding a partitioning key to partition the files on the DL helps and does increase query performance, also found that doing the same in Databricks in a df with partitioning returns data faster, not lightning but a noticeable performance improvement.
LikeLike
Finding a partitioning key to partition the files on the DL helps and does increase query performance, also found that doing the same in Databricks in a df with partitioning returns data faster, not lightning but a noticeable performance improvement.
LikeLiked by 1 person