
Change Data Capture (Referred to as CDC for the rest of this article) is a common pattern used to capture change events from source databases and push them to a downstream sink. Several services exist for such as an approach, but they commonly follow the pattern below –

Essentially, a change is made in the source database, some kind of log-reading mechanism kicks in that writes the changed row, with the associated operation (Insert, Delete etc) as an output.
CDC With Data Lakes
This method is fine and dandy, however in today’s ELT driven world of lakehouses and cloud data warehouses, data is normally ingested into the cloud platform as data files inside a data lake. Within the data lake our files are deposited according to a specific hierarchy, such as System/Table/Year/Month/Day/File.csv. Patterns vary, but typically looks like something like this –
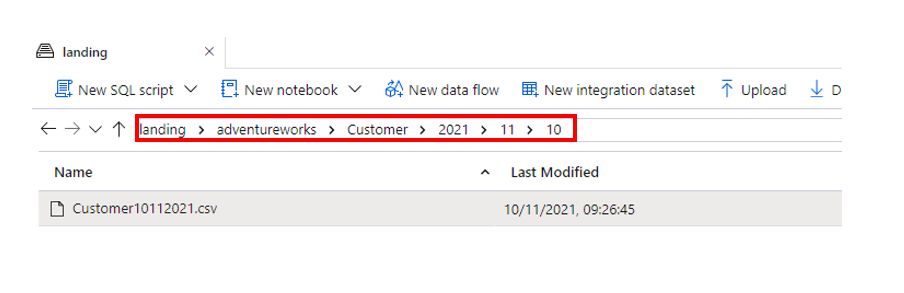
So in the case of CDC (and, incidentally, with any kind of incremental load pattern), we need to be able to handle the following processing logic on the data lake –
- Take all the files that have landed
- Process them to get the “net” changes – ie, what does the row look like after all the DML changes
- Load that into a master table that reflects the source table it came from
- Avoid having to reprocess all the previously processed files
It’s these requirements above that this article covers. Note, this generally isn’t an issue with “append” type changes as these can be appended to downstream tables. However, if your interest is taking CDC files from a data lake and upserting them into a target table so that it matches your source, please read on!
Pattern 1 – Databricks Auto Loader + Merge

This pattern leverages Azure Databricks and a specific feature in the engine called Autoloader. This feature reads the target data lake as a new files land it processes them into a target Delta table that services to capture all the changes. In the example below I’m tracking incremental files being created by Qlik Attunity in my data lake and processing them via Databricks.
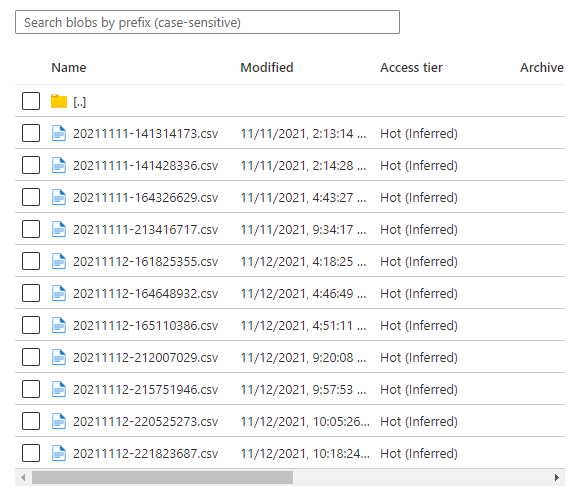
Each file contains changes created from the source system, with each row being a specific modification, such as INSERT, UPDATE and DELETE –

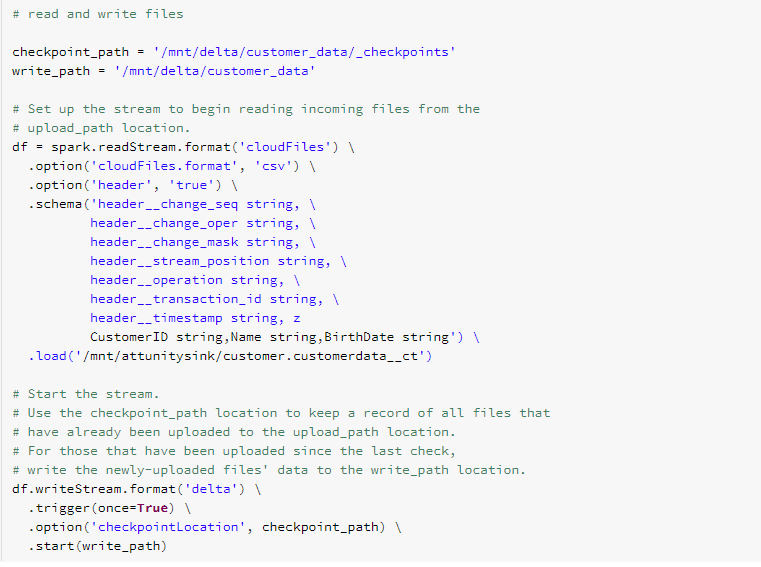
This is where auto loader comes in. By setting up an auto loader job to monitor the ingestion path, all files are processed as they land, with no need to build any kind of complex metadata handling. In the snippet below, I’ve setup an auto loader streaming job that reads the ingestion point and writes them into a delta table –
Reading the newly populated delta table we can see we’re capturing all our changes as they ingest into the data lake –
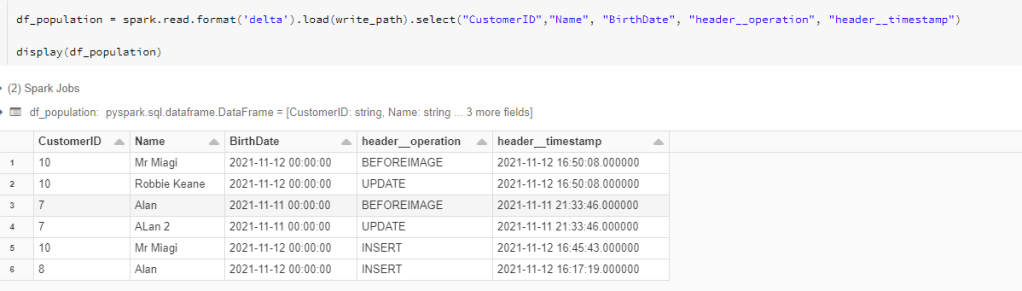
With our CDC data in our first delta table, we now need to transform that cdc data into a single row to represent the “net” changes. In the example above, Alan (Customer ID 7) changed his name to Alan 2, so there are 2 rows for his Customer ID. We only need the latest value of Customer ID 7 (“Alan 2”) to be merged into our downstream tables.
Thus, the second phase of this process then uses a SQL Merge statement (this can also be done in languages like Python if needed) with a MAX function to work out the net changes by row, and then merge them into the target Silver delta table (see Medallion architecture pattern). We create a delta table based on our CDC data –
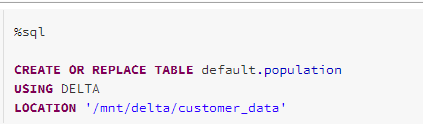
This table infers its schema from the data as shown above. We can then use it in our merge statement. In the example below, we create a silver table that will serve as our home of our sync’d net changes –
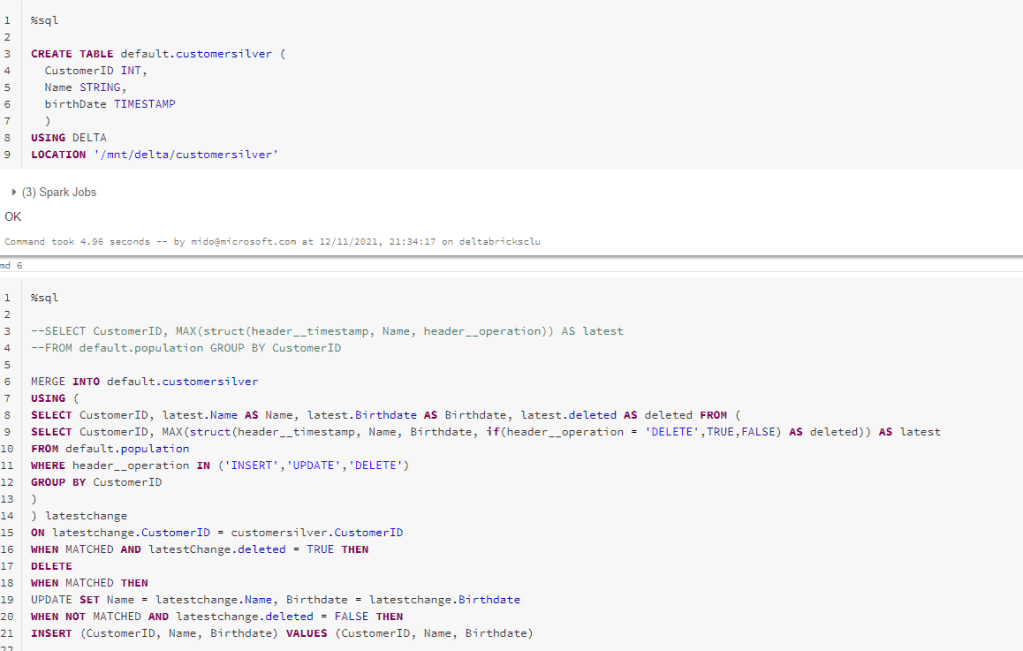
The above snippet does the following –
- Merges our source delta table containing all our CDC changes with our target silver table
- Uses a struct with the MAX function to get the most recent change based on our timestamp from CDC
- Filter our source table for INSERT, UPDATE and DELETE changes only (not prechange values)
- Join to our target table on a primary key. You could replace this with a HASH of all columns if you don’t have a native primary key
- If there’s a match, we update our silver table. If the source CustomerID is not found, we insert the new row into the silver table. If the row is deleted from source, we then delete from our silver table.
The net result in our silver table shows the latest view of each CustomerID –

Also, whilst this is technically a streaming pattern, you can configure Auto Loader to “Trigger Once“. This essentially means that rather than run this as a streaming pipeline, instead you run the process as a batch job that processes all the files that have built up since the last run and sinks them into the target delta table. This approach helps keep costs down and allows it to behave more like a batch processing job rather than a streaming job, which might be easier to incorporate into your data platform.
Pattern 2 – Synapse/Data Factory Tumbling Windows + Merge

This patter uses a different approach compared to the previous one. As there is no concept of “auto loader” in the Synapse platform (I’ll visit the Storage Event trigger in an upcoming post), instead the approach is here to use a clever trigger option within Synapse Pipelines/Data Factory that uses tumbling windows to process only the newest files in your data lake since the last run that are then processes downstream. How this differs from metadata-driven approaches is that you don’t need to craft some complex config schema/files to monitor which files have arrived and which ones need to be processed.
I’ll use a similar set of data as used in the previous example –
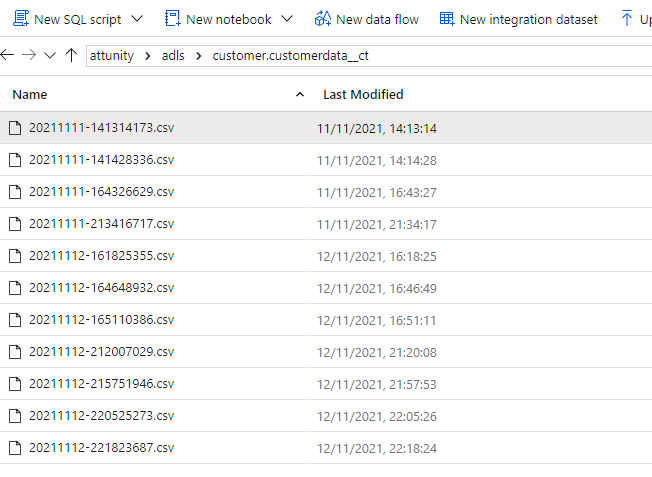
As stated above, we will be using a Data Factory/Synapse pipeline leveraging a tumbling window trigger to process new files. The trigger passes in a parameter based on the window start and end time for the given run, and these parameters are used on the target data lake to process files that have been created since the last window processed.
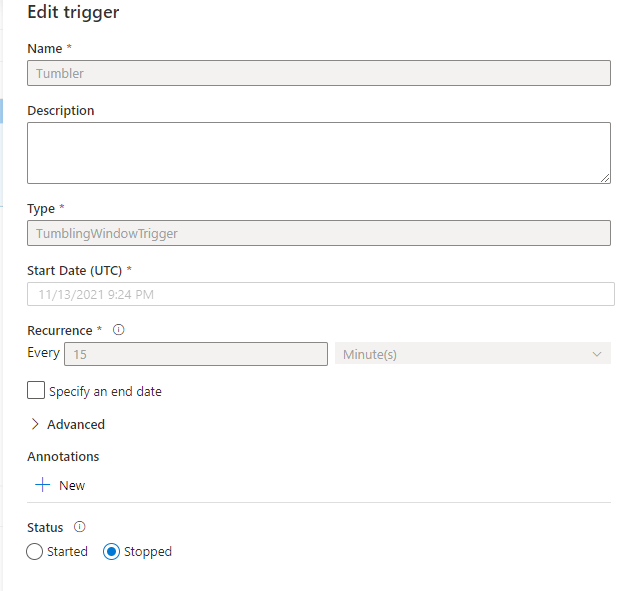
When the trigger runs, we can pass the window start and end dates as parameters to our pipeline –

And these are used in the Source Dataset which is based on our Data Lake storage –
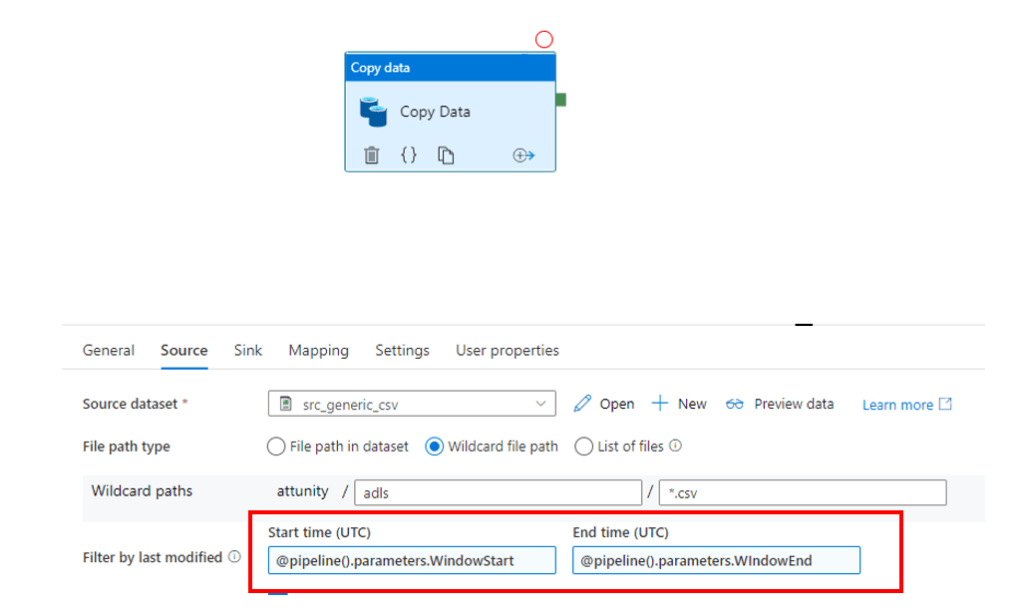
The tumbling window now runs on a schedule as above, as new files land in the data lake they’re picked up in a given window, and processed by the copy activity to a downstream Synapse staging table –
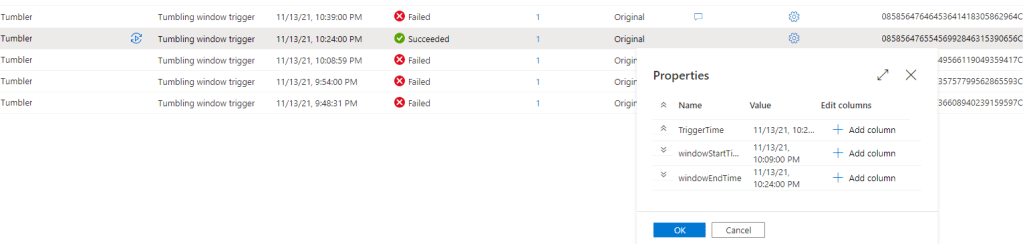
In this example, 2 update files had been dropped into our data lake, and this triggered the copy pipeline to trigger –
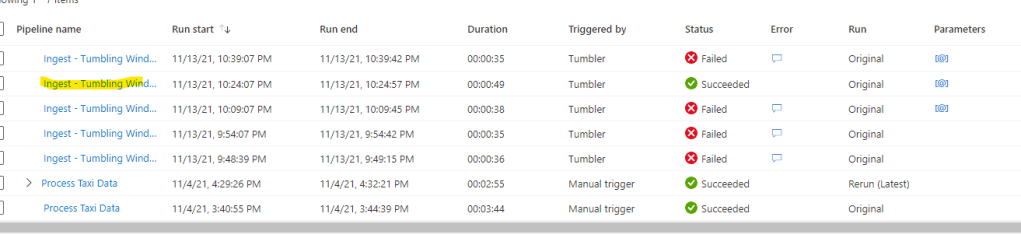
And for reference, the files were copied to a staging table in our Synapse Dedicated Pool by the ingest pipeline –

Querying my staging table I can see we’ve got 1 CustomerID with new changes captured (CustomerID 11, with a new name and birthdate) –
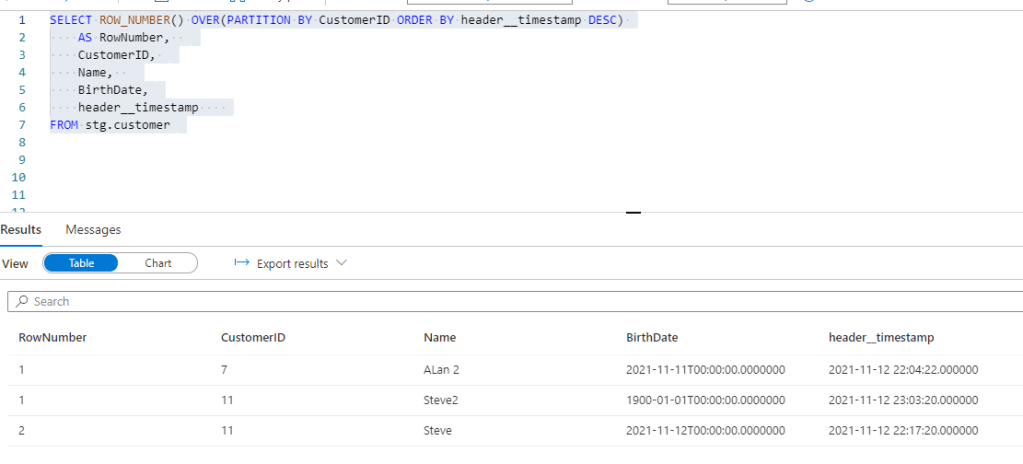
In the above I’m using the ROW_NUMBER function in Synapse pool to identify the latest row per CustomerID. For the record, window functions like this are some of my favourite in the entire SQL ecosystem, combined with MERGE :-). The function gives us the RowNumber output which can be used to select a specific member of the window based on other columns. In this case we partition by CustomerID (so it creates a “window” per CustomerID) and order by header__timestamp (so we can identify the latest version of the row). We add a filter on RowNumber to only return the most recent version of the row.
Finally, I do the same as in the Databricks example and put this query into my SQL statement to merge into my target Synapse Pool table –
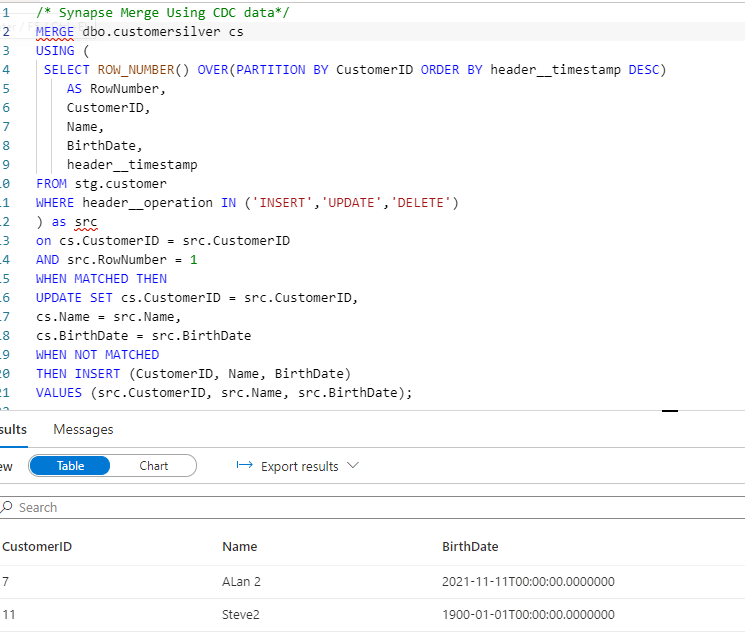
As you can see above, as a result of the MERGE + ROW_NUMBER function we only have our latest rows upserted into the target table.
You can now use this merged table with our latest rows as part of any subsequent ELT/analytics purposes.
Summary
Whilst there are many ways to skin this proverbial cat, these often involve some complex metadata-driven patterns to identify new files from the last run and then process them in the right order, update downstream tables, stamp the metadata audit tables etc.
The patterns show in this blog are two relatively simple examples using first party Azure services to handle CDC sources that are landing in your data lake. Both allow for the elegant and automatic ingestion of raw CDC files from your data lake and load them as single rows in a downstream operational data store/data warehouse. With the emergence of the lakehouse pattern the approaches cater for both and more “traditional” data warehouse type scenarios.
How do you handle your CDC ingestion? I’m always keen to hear how others have solved these kind of problems as they really allow for creative when architecting ingestion pipelines
Drop me a comment below!
Addendum
There’s also a feature called “COPY INTO” present in Databricks which allows for idempotent ingestion into the delta tables. This allows you to run your copy activities into the delta table without having to worry about reprocessing previous tables.
Databricks Live Tables (currently in private preview) also look to provide an interesting approach to this challenge. I’ll be blogging on this when they hit public preview.
Useful Links
https://docs.microsoft.com/en-us/azure/databricks/spark/latest/structured-streaming/auto-loader
https://databricks.com/blog/2018/10/29/simplifying-change-data-capture-with-databricks-delta.html

Excellent Mike. Enjoyed reading this.
LikeLiked by 1 person
Thanks Dave, glad it was useful.
LikeLike
great post mate
LikeLiked by 1 person