
We’re all largely familiar with the common modern data warehouse pattern in the cloud, which essentially delivers a platform comprising a data lake (based on a cloud storage account like Azure Data Lake Storage Gen2) AND a data warehouse compute engine such as Synapse Dedicated Pools or Redshift on AWS. There are nuances around usage and services, but they largely follow this kind of conceptual architecture –

In the architecture above, the key themes are as follows –
- Ingestion of data into a cloud storage layer, specifically in a “raw” zone of the data lake. The data is untyped, untransformed and has had no cleaning activities on it. Batch data typically arrives as csv files.
- A processing engine will then handle cleaning and transforming the data through zones of the lake, going from raw – > enriched -> curated (others may know this pattern as bronze/silver/gold). Enriched is where data is cleaned, deduped etc, whereas curated is where we create our summary outputs, including facts and dimensions, all in the data lake.
- The curated zone is then pushed into a cloud data warehouse such as Synapse Dedicated SQL Pools which then acts as a serving layer for BI tools and analyst.
This pattern is very common, and is still probably the one I see most of in the field.
So far, so fantastic. However whilst this is the most common pattern, it’s not the unicorn approach for everyone. There are potential issues with this approach, especially around how we handle data and files in the data lake itself.
These perceived challenges led to the emergence of the “Lakehouse” architecture pattern, and officially emerged on the back of an excellent white paper from Databricks who are the founders of the lakehouse pattern in its current guise. This whitepaper highlighted issues as encountered in the current approach, and highlighted the following main challenges –
- Lack of transaction support
- Hard to enforce data quality
- It’s hard/complicated to mix appends, updates and deletes in the data lake
- It can lead to challenges around data governance in the lake itself, leading to data swamps and not data lakes
- It has multiple storage layers – different zones and file types in the lake PLUS inside the data warehouse itself PLUS often in the BI tool also
So what is the Lakehouse?
In a nutshell (and this is a bit of an over simplification but will do for this article) the core theme of the Lakehouse is 2 things –
- There is no separate data warehouse and data lake. The data lake IS the data warehouse
- Delta Lake – This is the secret sauce of the Lakehouse pattern and looks to resolve the challenges highlighted in the Databricks whitepaper. More on this below.
The conceptual architecture for Lakehouse is shown below –

You can see that the main difference in terms of approach is there is no longer a separate compute engine for the data warehouse, instead we serve our outputs from the lake itself using the Delta Lake format.
So what is Delta Lake, and why is it so special?
The Delta Lake (the secret sauce referred to previously) is an open source project that allows data warehouse-like functionality directly ON the data lake, and is summarised well in the image below –

The Delta Lake provides ACID (atomicity, consistency, isolation and durability) transactions to the data lake, allowing you to run secure, complete transactions on the data lake in the same way you would on a database. No longer do you have to manage files and folders, worry about ensuring data in the lake has been left in an consistent state etc. Delta just manages it for you.
With features such as Time Travel it allows you to query data as it was at a previous state, such as by timestamp or version (similar to SQL temporal tables).
Delta provides the ability for tables to serve as both a batch AND streaming sink/source. Before you had to create complex lambda architecture patterns with different tools and approaches – with Delta you can unify this into one, much more simplified architecture.
Schema Enforcement allows us to define typed tables with constraints, data types and so forth, ensuring our data is clean, structured and aligned to specific data types.
CRUD – With Delta, modifying, adding and deleting data is MUCH easier. Using SQL, Python or Scala methods you can apply data transformation without having to manipulate the underlying data lake. Basically, if you can write an UPDATE statement in SQL, you can use Delta.
How Does Synapse Analytics Support Lakehouse?
Synapse Analytics provides several services that enable you to build the Lakehouse architecture using native Synapse services. It’s worth calling out you can obviously do this using Azure Databricks too, but this article specifically is aimed at those users looking to use the full range of Synapse services to build it on that platform specifically.
For those who don’t know what Synapse is – in short, it’s a unified, cloud native analytics platform running on Azure that provides a single pane of glass approach that exposes different services and tools depending on use case and user skills. These range from SQL pools through to Spark engines through to graphical ETL tools plus many others. In short, Synapse can do it all –
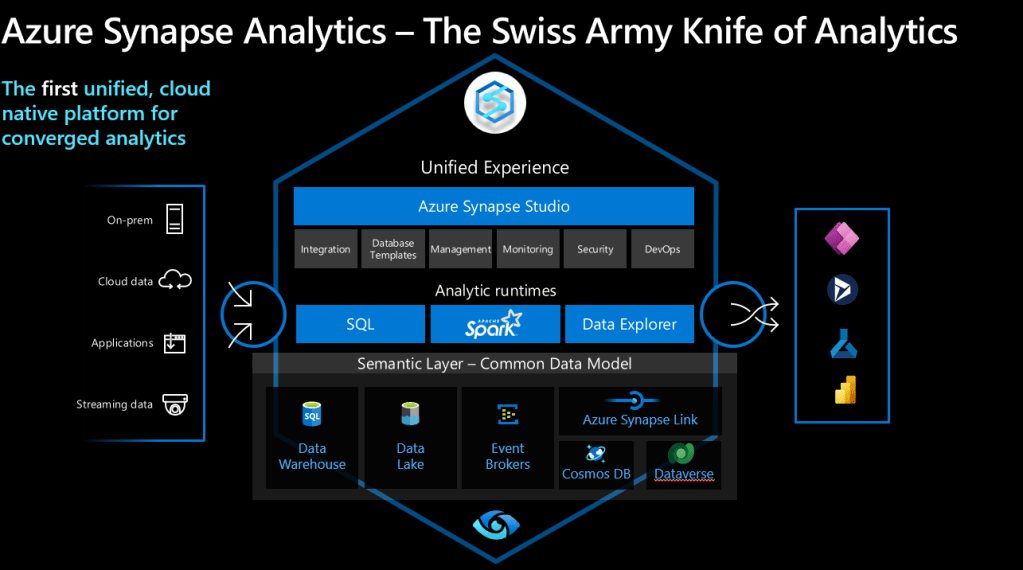
Whilst there are many services in Synapse, the main ones to call out for the Lakehouse in particular are the following –

Synapse Pipelines (essentially Data Factory under the Synapse umbrella) is a graphical ELT/ELT tool that allows you to orchestrate, move and transform data. Pulling data from vast amounts of sources, you can then ingest, transform and load your data into the Lakehouse.
In terms of Lakehouse specifically, Synapse Pipelines allow you leverage the Delta Lake format by using the Inline Dataset type that allows you take advantage of all the benefits of Delta, including upserts, time travel, compression and others.

Synapse Spark, in terms of the Lakehouse pattern, allows you to develop code-first data engineering notebooks using the language of your choice (SQL, Scala, Pyspark, C#). For those of you who like developing code-driven ELT/ELT, Spark is an excellent and versatile platform that allows you to mix and match code (eg do a powerful transform in pyspark, then switch to SQL to do SQL-like transforms in the same data) and operationalise the notebook via Synapse Pipelines.
Similar to Synapse Pipelines, Synapse Spark uses Spark runtime 3.2, which includes Delta Lake 1.0. This allows you take advantage of the full capabilities that Delta provides.

The final main service I want to call out is SQL Pools – specifically Serverless SQL Pools – in the Lakehouse pattern. Synapse already has the concept of Dedicated SQL Pools, which are provisioned, massively-parallel processing (MPP) database engines designed to serve as that main serving layer.
In Lakehouse however, we don’t use a Dedicated SQL Pool. Instead, we leverage the other SQL Pool offering inside Synapse, namely Serverless SQL Pools. These are ideal for Lakehouse as they’re pay-per-query, not always-on compute, and they essentially work by creating a T-SQL layer on top of the data lake, allowing you to write queries and create external objects on the lake that external tools can then consume.
In terms of Lakehouse, Serverless SQL Pools have support for the Delta format, allowing you to create external objects such as views and tables directly on top of those Delta structures.
Synapse-centric Lakehouse Architecture
So, with that background in mind, how does this translate into a Synapse-centric logical architecture?

The above shows how we translate those services into an end-to-end architecture using Synapse and Delta Lake platform.
In short, we have –
Data ingested in batch or stream, written to the data lake. This data is landed in a raw format, such as csv from databases, json from event feeds. We don’t use Delta until Enriched onwards.
Synapse Spark and/or (It’s not a binary choice) Synapse Pipelines are used to transform the data from raw through to enriched and then curated. Which tool you use is up to you, and will largely depend on use case and user preference. Cleansed and transformed data is persisted in the Delta format in Enriched and Curated zones, as it’s here where our end users will have access to our Lakehouse.
The underpinning storage is Azure Data Lake Storage Gen 2, which is Azure’s cloud storage service optimised for analytics and integrates natively with all the services used.
The Delta tables created in Enriched/Curated and are then exposed via Serverless SQL objects such as views and tables. This allows the SQL analysts and BI users to analyse data and create content using a familiar SQL endpoint that is pointing to our Delta tables on the lake.
Data Lake Zones
Inside the Data Lake itself, we can take a deeper look at how the raw/enriched/curated zones are actually mapped –

The Landing zone is a transient layer that may or may not be present. It’s often used as a temporary dump for daily batches before being ingested into the raw layer. In the latter we often see data stored in subfolders in an append approach, such as AdventureWorks/Customer/Year=2022/Month=Jan/Day=31/customer.csv, as the aim here is not replace/overwrite, but just to append.
Following raw, we see enriched and curated zones now in the Delta format. This applies all the benefits of Delta, and, more importantly, creates that metadata layer that allows data to be access/modified/used with other tools via the Delta api.
ELT Approaches to the Lakehouse
I’ll now take a brief tour that summarises the the approaches in more detail – specifically, how we ingest, transform and serve the data in Synapse, using this Lakehouse pattern.


Ingestion for both streaming and batch is largely the same in the Lakehouse as it is in the Modern Cloud DW approach. For streaming, we ingest using a message broker engine such as Event Hubs, and then have transformation options on the stream using Stream Analytics or Synapse Spark. Both read from the event hub queue and allow you to transform the stream in SQL, Pyspark etc, before landing in a sink of your choice.
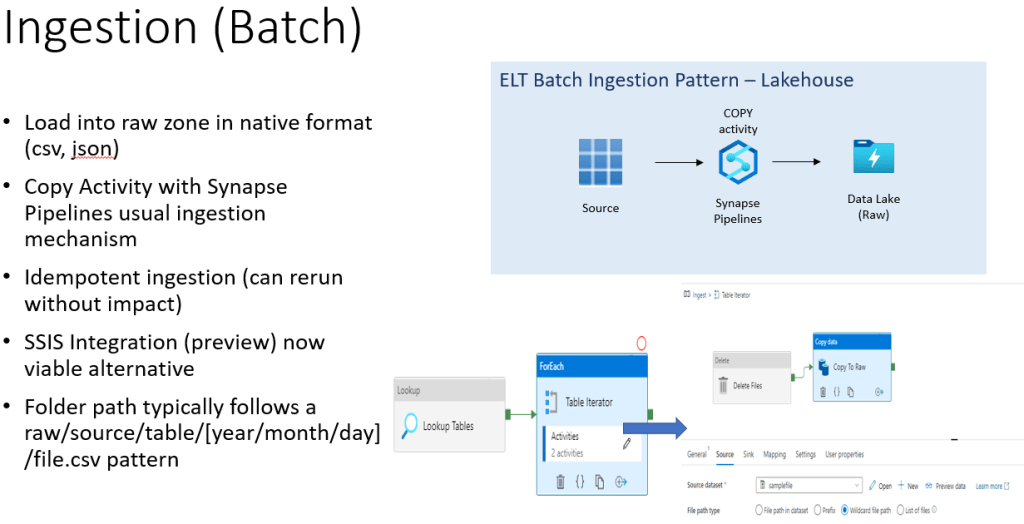
When ingesting in batch, the recommended tool is Synapse Pipelines and specifically the Copy activity. This allows you to copy data from 95+ different connections and land them into the raw zone of the data lake.
Recommended production patterns are to go for metadata-driven frameworks that greatly reduce the amount of pipelines and activities you need to create, and instead drive copy sources and sinks via metadata and dynamic pipelines. Synapse provides one out of the box, but there also community frameworks that are extremely powerful.
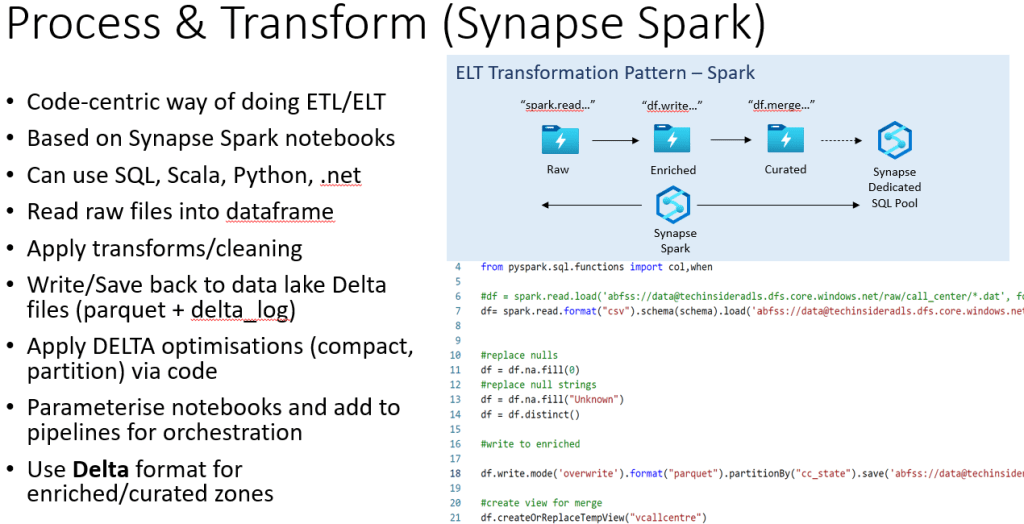
It’s in the Process & Transform area where we have multiple choices. You can mix and match as needed, depending on use case and preferences.
Using Synapse Spark as one option, you read your data into Spark dataframes and then apply transforms to shape the data into the structure that’s needed.
Once completed, you write the cleansed and processed data back into the Lakehouse into your enriched and curated zones respectively as DELTA files (technically a DELTA table is parquet files with a _delta_log that tracks changes, see here for more details).
In general, enriched is normally for the cleansed and tidied up version of raw (i.e. remove nulls, clean bad data, some light transforms and lookups) and curated is where you serve your business-level outputs, such as facts, dimensions and other analytical datasets.
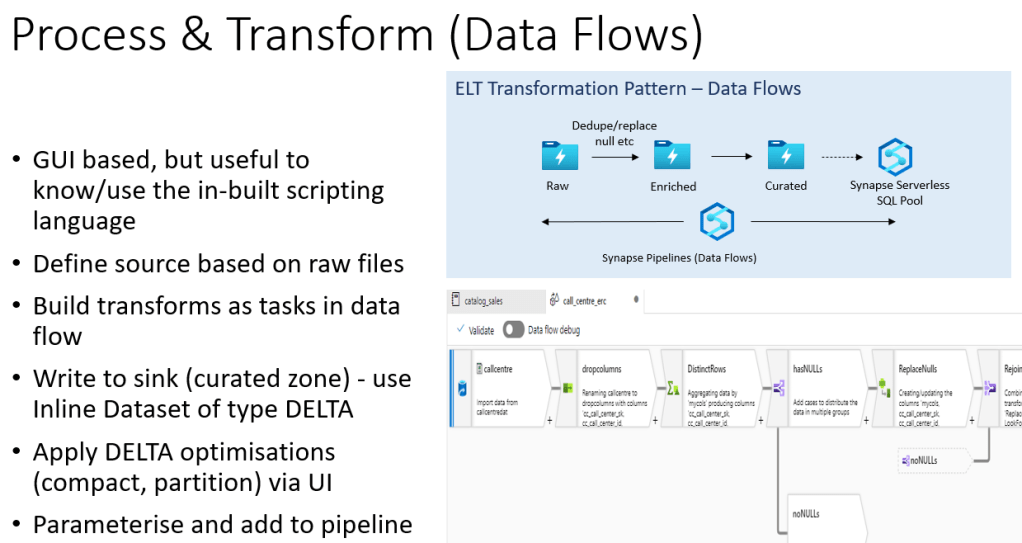
Using data flows, we can apply the same transforms and cleansing as we do with Synapse Spark, but instead we do it via a GUI in the data flow canvas. For those users coming from ETL tools such as SSIS or Talend, this might be a preferred approach to coding data pipelines in Spark notebooks.
In Data Flows, you define your source, then apply a series of transformation tasks on the data before finally loading it into your Lakehouse in the Delta format.
As with Spark notebooks, you can then parameterise the flow and add it your Synapse Pipelines.

Finally, we now have the option of creating persisted tables using what’s called CETAS (Create External Tables as Select) statements.
Whilst Serverless SQL Pools are not a data store in themselves (they provide a SQL layer on top of data lake), they do provide a functionality to write commonly used queries back into the data lake as a persisted table. This CETAS functionality is very useful if an analyst has created a SQL query in Serverless SQL that perhaps is quite complex or has a lot of joins. By persisting it via CETAS it writes the output of the Select statement to data lake and exposes it as an external table for other users to use.
As the query is persisted, this is generally much more performant than the original complex query with many joins etc.
CREATE EXTERNAL TABLE salesbyproductcategory
WITH (
LOCATION = 'aggregated_data/salesbyproductcategory/',
DATA_SOURCE = datalake,
FILE_FORMAT = ParquetFileFormat
)
AS
SELECT p.ProductCategoryName, sum(s.linetotal) as TotalSales
from DimProduct P inner join FactSales S on p.productid = s.productid
group by p.ProductCategoryNameAbove, we see an example of a CETAS statement that takes the query defined, and persists the output to the data lake and exposes it as an external table called “salesbyproductcategory” via the Serverless SQL Pool.

Finally, we now create our external objects in the Serverless SQL pool to expose them for access by BI tools and SQL analysts. (Synapse does have a shared metadata model where tables created in Lake Databases sync automatically to Serverless SQL Pools. At the time of writing this isn’t supported for Delta (just Parquet and csv), but is on the roadmap. Hence, we need to create the external objects with this extra step).
Essentially, we define views using the Openrowset functionality (see above) that “points” to the underlying Delta table (Factsales in the example above). This then exposes the FactSales view in the Serverless SQL pool for use by external tools.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create procedure [dbo].[sp_create_external_objects] (@table varchar(1000))
AS
begin
declare @sql NVARCHAR(4000)
set @sql = 'Create or alter view '+ @table + ' AS '
set @sql = @sql + 'SELECT * FROM OPENROWSET(BULK '
set @sql = @sql + '''https://sqlbitsdatalake.dfs.core.windows.net/datalake/sqlbitsdemo/curated/'
set @sql = @sql + @table + ''', FORMAT = ''DELTA'') AS [result]'
exec sp_executesql @sql
end
GO
From there, we extend this by creating a stored procedure that creates our external objects dynamically. There are a few ways of doing this, but the example below shows a “Get Metadata” activity to read the child items of my curated folder, then passing that name to the stored procedure above that then creates the view based on the table name and location passed to the procedure.
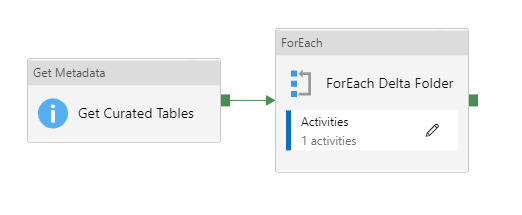
Drilling into the Get Metadata activity, we see it obtains child items from the curated zone –

Before passing that item through to the stored procedure –
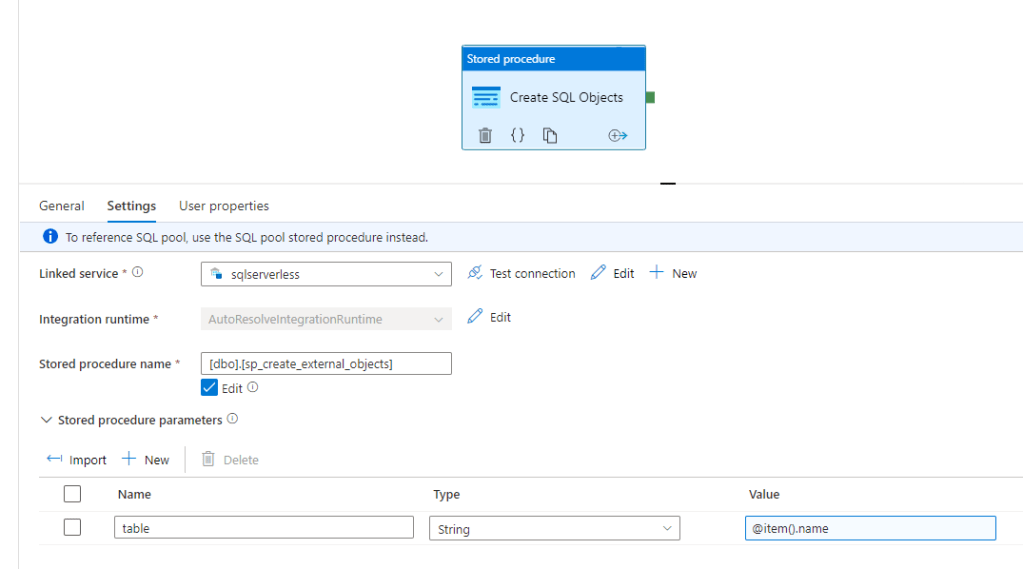
When this is run, it creates our external objects in the Serverless SQL Pool –

Bringing it all together
And at last, like Frodo and Mount Doom, we reach the end phase of this article. With the above activities in mind, we finally bring them together as a series of pipelines that chain the different tasks of ingestion, transforming, creating and serving together –

And we can view these objects in our tool of choice, such as Power BI or SSMS –
Summary
This article has been a summary of how to build the Lakehouse architecture using Synapse Analytics. At the time of writing (March 2022), there are a lot of extra features being added to Synapse, especially in the Lakehouse space. New additions such as the Lake Database and Database templates, when coupled with the shared metadata model, will only go and enhance the Lakehouse capabilities already present.
Finally, this article is definitely not me saying you must abandon your cloud data warehouse! Far from it! The Lakehouse pattern is an alternative architecture pattern that doubles down on the data lake as the main analytics hub, but provides a layer on top to simplify historical challenges with data lake-based analytics architectures.

Great story! this doesn’t seem to be an end-to-end demo which would help adoption significantly. Any links on seeing it in action?
LikeLike
Thanks Drew! I totally agree! I’m doing a talk/demo at sqlbits this weekend then I plan to adapt and upload to show it end to end – watch this space 😊
LikeLike
Hey Mike, is there any way I can rewatch your talk at sqlbits? I can’t find the demo online. Thanks in advance!
LikeLike
Hi David, ah OK I’ll check, I thought they put all the content out on demand but can’t see it now. Will ask the organisers
LikeLike
Hi Mike, Were you able to find your talk from sqlbits? Can you share that link please? Great article here, but would like to see the demo, especially for the Curated layer design! Thank you for you work!!
LikeLike
Hey – sorry for the delay in this – the recording is now available here – https://sqlbits.com/Sessions/Event22/Building_the_Lakehouse_Architecture_with_Azure_Synapse_Analytics
LikeLike
Thanks for this golden pot of knowledge sharing Mike. Indeed, delta is a wonderful secret sauce. However, let’s assume production performance requirements and features such as native row level security/column masking are a necessity. This rules out the serverless sql pool.
However, unless I’ve missed something, there seems a lack of Synapse options to bulk insert the lake delta into a dedicated pool table. An integration dataset cannot be created for a lakehouse delta table. The only way I’ve been able to achieve lake delta to sqlpool dedicated table is via a spark notebook, using the scala synapse dedicated pool connector:
https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/synapse-spark-sql-pool-import-export
Any thoughts?
LikeLike
Hi JP, you can also copy data from delta to a dedicated pool using mapping data flows and the inline dataset type of delta.
https://docs.microsoft.com/en-us/azure/data-factory/format-delta
LikeLiked by 1 person
Worked like a charm, and was able to keep my hash distribution config by just truncating the table in the sink node of the mapping data flow. Must admit however I didn’t find it immediately intuitive to use an Azure Synapse Analytics linked service to specify the dedicated sql pool. Thanks Mike!
LikeLike
Thanks Mike for this comprehensive article. We plan to use both Lakehouse and Dedicated Pool to satisfy different performance requirements and keep dedicated pool smaller. So Lakehouse is used for Power BI import data sets (where performance is not such an issue for us) and dedicated pool for ad-hoc queries and direct query Power BI. Does this approach make sense to you? I can see JP in comment above plans to do something similar, but I’ve never seen this pattern described by Microsoft.
LikeLike
Hi Martin,
Yes the approach makes sense. The benefit of this multi layered architecture is that you can use the right layer for the right job. As long as you have good data governance approaches for your ELT pipelines that load the dedicated pool from the data lake it should be fine – what you want to avoid is analysts creating different versions of the base data and then comparing the two (eg building a summary dataset from the data lake and comparing with one already in the dedicated pool) when they’ve created their own data rules etc – so using features liked certified datasets in power bi, and the features of purview can really help that.
But as an approach, that works fine, and like you say helps to keep the dedicated pool leaner and used for what it’s best for.
LikeLike
Great article @Mike
LikeLike
Hi Mike, for the lakehouse solution , do we need to star-schema in curated layer(includes scd2)?
LikeLike
Hey cc,
No necessarily – although for a your enterprise serving layer I would recommend a star schema as it’s optimised for end users, is a tried and testing approach and works well with BI tools such as Power BI.
What I do see a lot in this kind of lakehouse pattern though is many “reporting datasets” in the gold layer – so if you’ve got a common dataset of summary aggregates by certain dimensions, as an example, then this can often be persisted as it’s own dataset in the serving layer.
LikeLike
Nice article!
LikeLike