Been a while since my last post – got a few in the backlog now though so will have a trickle of articles coming through in the next few months.
This short one is about a feature that (from my experience) isn’t as well-known as others in the toolset and is one that is of really good use for those data engineers building graphical ETL/ELT pipelines in Mapping Data Flows in Data Factory/Synapse Pipelines.
The feature I want to touch on today is the “Assert” transform in Mapping Data Flows, which, as described in the official docs, provides the following functionality –

In this brief article I’ll show a quick example of how to set up an Assert transform and how to include it as part of a data loading pipeline.
First, you’ll need to create a data flow – The assert is part of the mapping data flow functionality, so create a data flow to begin with.
In your data flow, add in the Assert transform, connecting it to the upstream data source that you want to perform the assert against –
In this example, I’m going to do a simple uniqueness check. I’m cheating a little as I’m using a column that will always have duplicates (the SalesOrderID in the FactSales table from Adventureworks) but this will do to show the example.
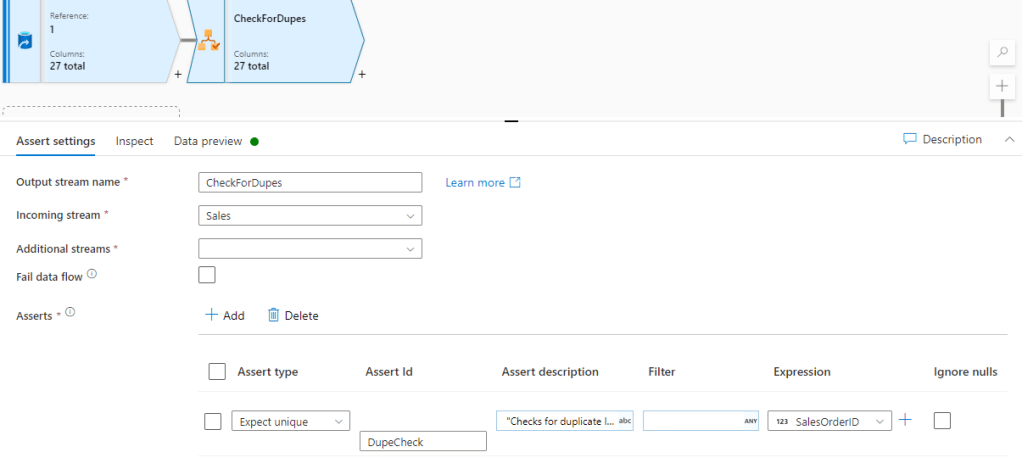
I set the assert up as follows, using the “Is Unique” check and passing in the column to check against. The AssertId is a unique name I assign to the specific each assert so I can reference it downstream.
Note, I can have multiple asserts but today I’ll just use one example –
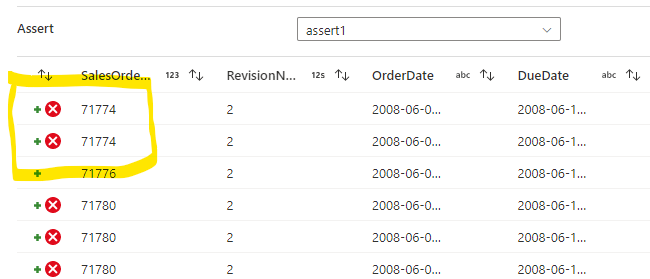
If I now run the data preview I can see the assert has “failed” several rows where there is a duplicate of the SalesOrderID –
Dealing With Assert Output
Now I’m getting my rows checked and the assert identifying the failed rows based on the constraints I defined, I now need to do “something” with the failed rows as part of my pipeline.
The very simplest way to handle them is that I can check the box to make the flow fail in the event of an assert failure. Whilst this may be a good solution for some scenarios, in an ideal world I want to allow my data flow to complete without triggering an actual hard failure.
Therefore, the simplest way to deal with the output of assert failures without failing the flow is to prevent them to loading into the Sink, so in this example below, I can disable the “Output to Sink” checkbox under Assert Failure rows as per the below –

This will prevent the failures being loaded to the sink (I can also output them to a separate file entirely) –
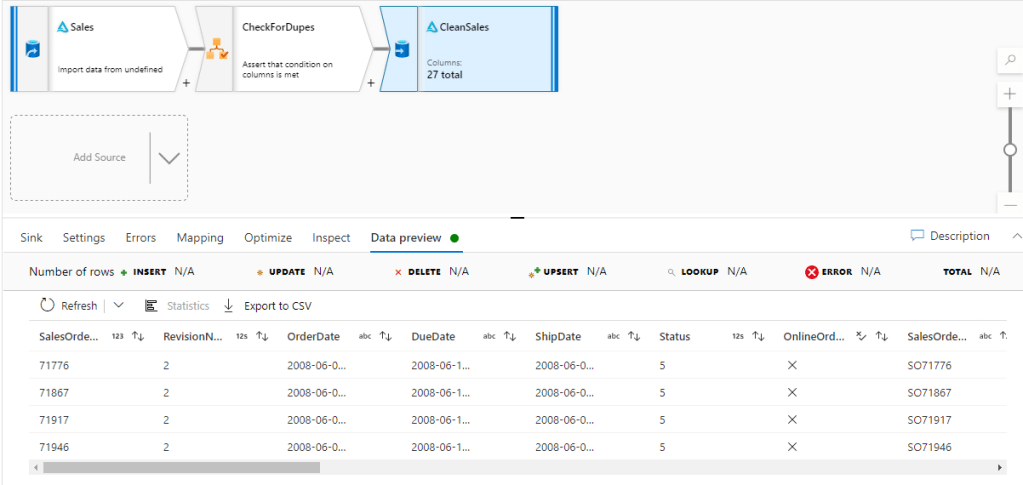
As we can see in the above, only the rows with no duplicates have flowed through to the sink.
Advanced Assert Output Handling
If the above approach is too simple and you need to do some more advanced downstream handling of the assert output, you can use further transforms such as Conditional Split or Filters to divert rows in difference directions. See below for an example using Conditional Split –
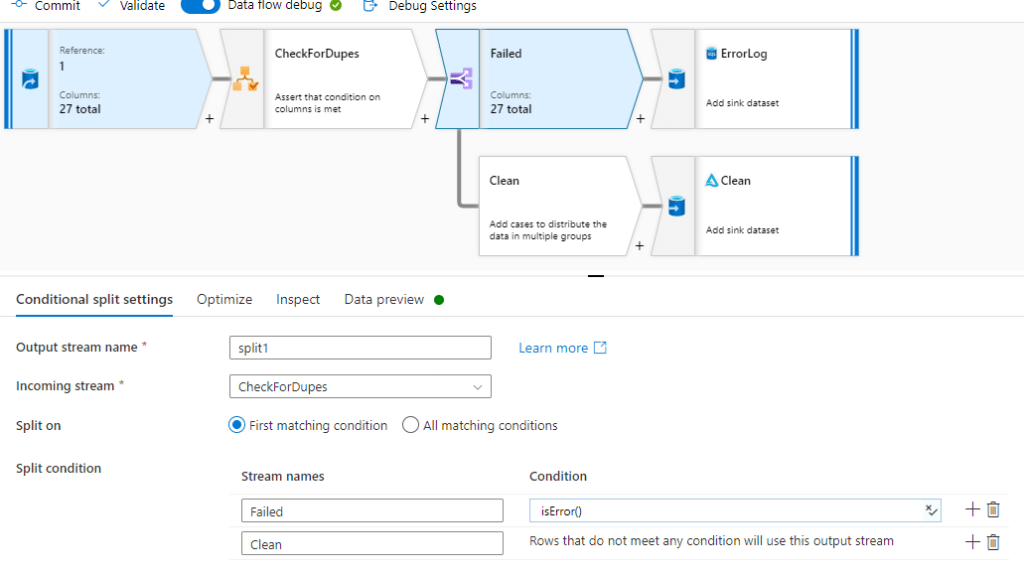
The flow (both failed asserts and clean data) can then be directed as you see fit, with the example above diverting error rows to a sql database for analysis, and clean rows going into our delta lake –
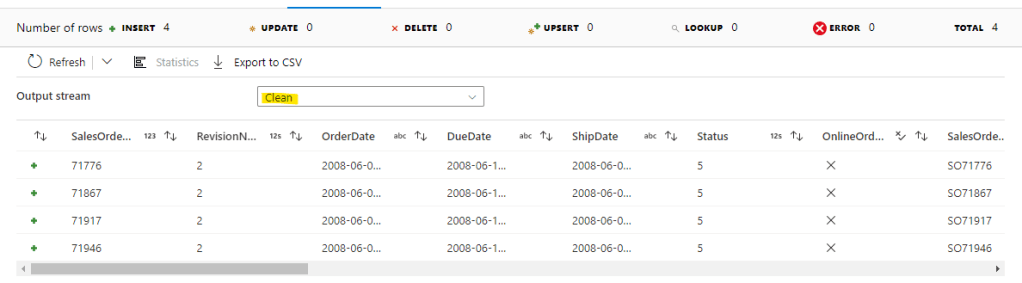
Summary
Whilst there are many ways (as always) to approach this kind data quality and validation checking as part of a data pipeline in Azure, the Assert Transform gives excellent out of the box capability to add to build powerful DQ features as part of your graphical ETL/ETL workload.
References
https://docs.microsoft.com/en-us/azure/data-factory/data-flow-assert
